| Version 3 (modified by , 10 years ago) (diff) |
|---|
Metadata Quality Assessement Service
This is a draft proposal for a service that assesses the quality of metadata descriptions (or schemas) based on a number of defined metrics. ("quality" in this document and context is always meant as relative to the defined criteria.)
This effort is part of the metadata curation taskforce. Parts of this document are taken from the paper Trippel et al. Towards automatic quality assessment of component metadata to be presented at LREC 2014
Requirements
- work as a standalone service AND as a module that can be integrated with tools like metadata editors
- be able to evaluate both schema (profile) and instance (md record)
- evaluate both one record and whole collection (in batch mode)
- be aware but not dependant on the Component Metadata model
- inspect URLs (both in cmd:ResourceProxy and in record body) wrt to their availability
- robust awareness of semantic grounding mechanisms (concept-links / data categories (not relying solely on the CMD way of indicating semantics))
- output a simple score AND detailed verbose justification
- summarized result for a collection of records
Usage Scenarios
The service is expected to be integrated into the post-processing workflow of the metadata harvesting by the main CLARIN harvester, with subsequent conveying of the results back to the content providers, effectively establishing a closed feedback loop.
We can distinguish between following scenarios for the usage of the system:
- Measuring the quality of one record at editing time
- provides a person creating the metadata with immediate feedback on the amount of additional data necessary to receive a better score.
- Evaluation of a specific repository
- evaluating the overall quality of the metadata included in a given repository provides feedback to those running a repository
- Overall overview of the metadata quality within the joint MD domain
- an aggregation over all harvested metadata records (ideally with possibility to inspect the results by various means (grouping by profiles, collections, selected data categories or any other facet)
Additionally to the above scenarios pertaining to the instance level, there are further use cases on the schema level, the results of the profiles and components evaluation being valuable information for the metadata modeller:
- Ranking of profiles/schemas (and components)
- Applying the schema level assessment on all defined profiles and components yields a ranking that assists the metadata modeller to choose the right one
- On the fly quality assessment of the profiles being constructed
- gives the modeller an indication of its quality
also showing shortcomings, it is anticipated that the repository as such should also be evaluated by the average score of the resources provided and the number of profiles and resources.
Interface
Input
one of:
- one metadata record
- whole collection
- CMD profile
- metadata schema
Output
- verbose response listing the assessed aspects and explaining the shortcomings
- a summarized result in case of the assessment of multiple records (whole collection)
- some score (how to compute?) would need to apply some normalization and weighting on the outcomes of individual inspected aspects
However, though in principle a score could be computed in a way that the scale is closed, we propose an open scale, especially as a full score would seem problematic as leaving out or filling in optional elements would lead to distortions of the score.
Inspected/Checked aspects in detail
(Aspects with questionmark are subject to discussion)
Schema level
- presence of "required" data categories
- ratio of elements with data categories
- size?
- ?
Instance level
- availability of the schema
- validity of the record wrt to the schema
- links are resolvable
- filled-in ratio?
- how many of the elements defined by schema are actually populated with information
- values conform to a controlled vocabulary
- size e.g. overall size (measured in characters)
- ?
Implementation
There are already a few prototypical applications that tackle some of the functionality discussed here:
Thorsten has developed a prototypical implementation of the assessment tool in XQuery. (Code not public yet.)
Oliver Schonefeld (IDS) has developed an on-demand OAI-harvester meant for the data providers
to be able to quickly test their OAI endpoints:
https://clarin.ids-mannheim.de/metadata-inspector/ (Note: this application is a very early prototype, so expect bugs or unimplemented functions)
Jozef Misultka (LINDAT) also built an on-demand OAI-harvester. (OS: he showed it to me in Prague; I don't know about the current state of the tool. The task-force might want to contact him about this)
Oliver also works on a small high-performance command line tool that schema validates the CMDI-records. (The code will be put into CLARIN repository shortly.)
Issues to discuss
- "required" data categories
- operate on XSD OR CMD?
- evaluate also components or just whole profiles?
- How to reflect size?
Too little is not good, but too many (fields) is also problematic
- number of elements
- number of filled-in elements
- number of distinct values in a field
- Further measures could be derived from background knowledge (i.e. if the system remembers other assessments, it could put results in relation to previous results from other batches/providers.)
- How to compute an overall score?
- Format of the output
"Required" data categories
Minimal set of data categories that are deemed important for further processing of the record, especially wrt to retrievability in existing search interface (like VLO)
List of candidate categories:
- resource title or name
- modality
- resource class
- genre ?
- keywords or tags
- country (which?)
- contact person,
- publication year
- availability / licence
Attachments (2)
-
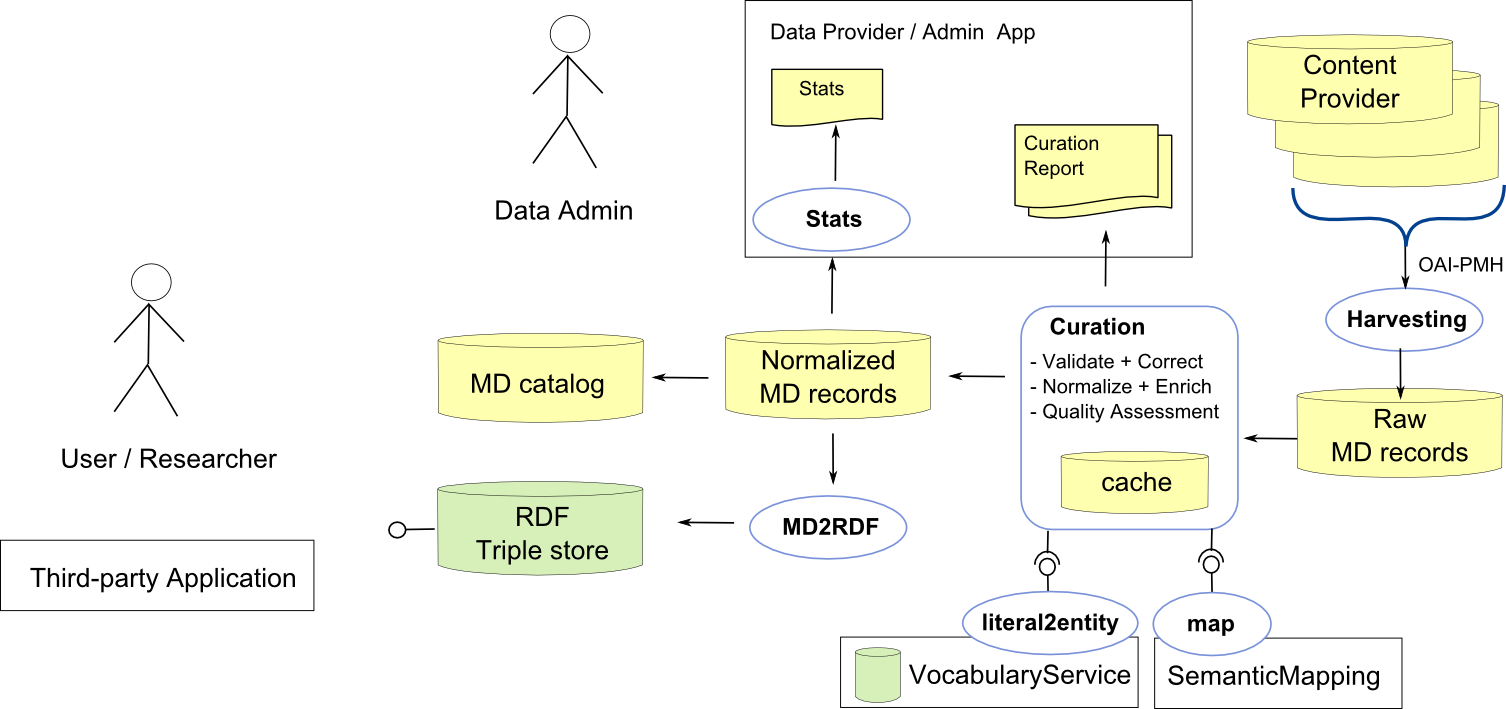
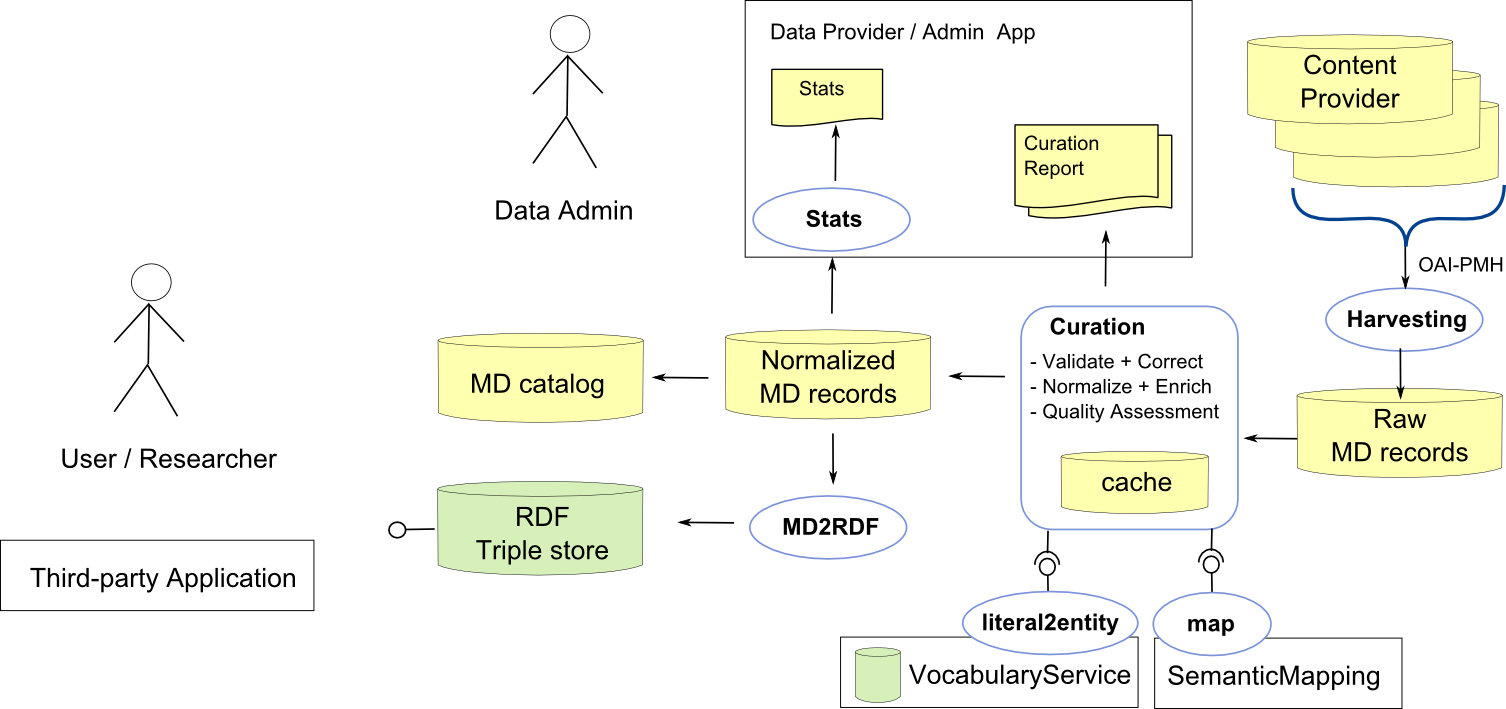
DHKnowHub.png (150.3 KB) - added by 10 years ago.
Sketch of a generic processing workflow for metadata from harvesting via curation to presentation
-
MDflow.png (150.3 KB) - added by 10 years ago.
Sketch of a generic processing workflow for metadata from harvesting via curation to presentation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip