| Version 6 (modified by , 10 years ago) (diff) |
|---|
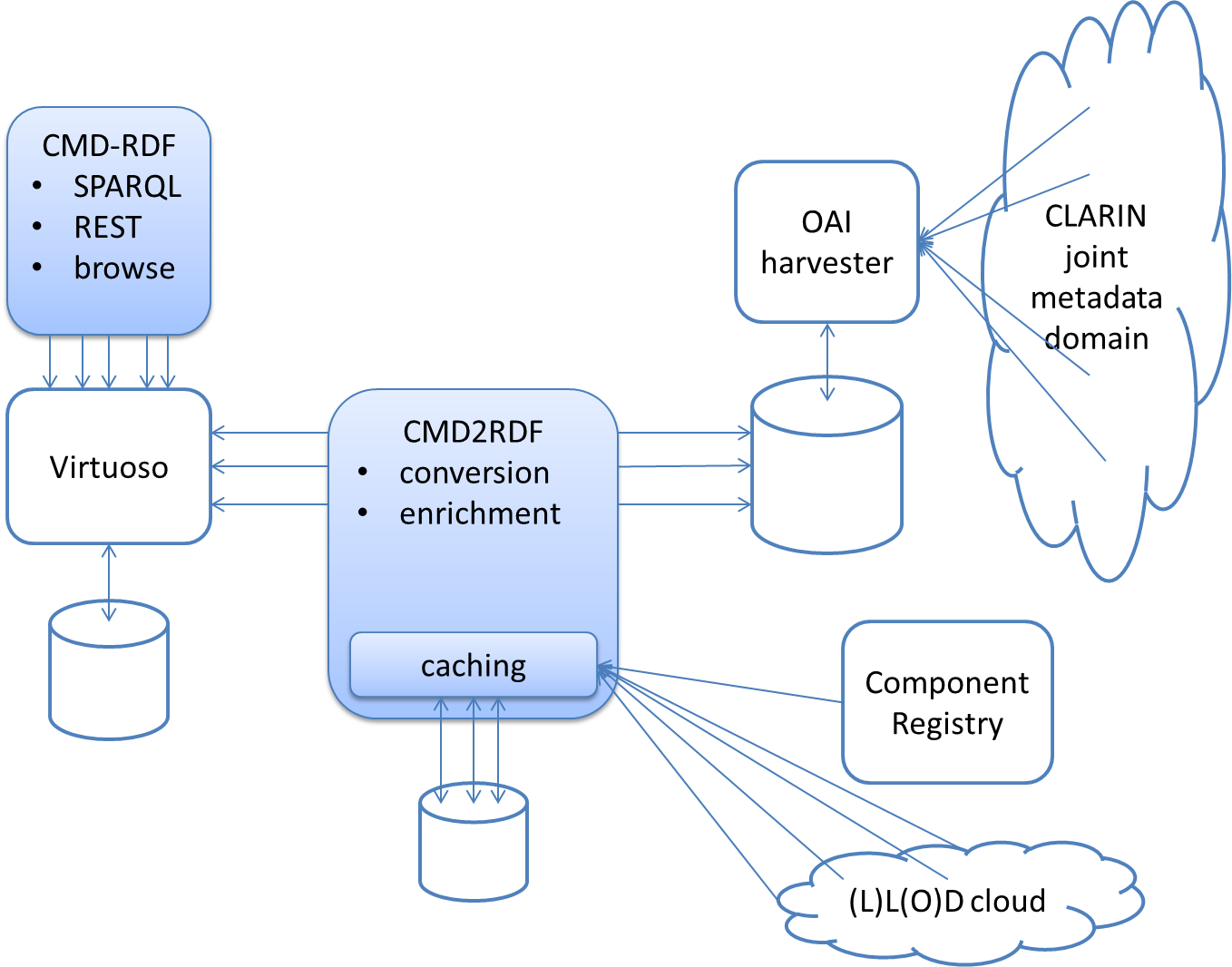
CMD2RDF system architecture
This page describes (a first sketch of) a system architecture for CMD2RDF. The aim of this architecture is to be able to keep the RDF(S) representation of CMDI up-to-date with the growing CLARIN joint metadata domain and offer stable services on top of that. The following figure provides a high level overview:

The OAI harvester regularly collects all CMDI records from the CLARIN joint metadata domain and stores it on the catalog.clarin.eu servers filesystem for other tools, e.g., the VLO importer or CMD2RDF to pick up.
CMD2RDF
In initial stages sample sets of CMD record have been converted to RDF and this showed several bottlenecks/problems:
- the conversion of an record needs access to the profile, when this access isn't cached the Component Registry gets overloaded;
- using a shell scripts means, when Saxon is used, JVM upstart time and XSLT compilation costs for each conversion.
Costs of this can be lessened by using SMC scripts for caching profiles and running the XSLT. Still it's expected that we can gain more (and will need to because the growth of the number of CMD records harvested) performance by developing a multi-threaded special purpose Java tool. The CMDIValidator tool can be used as basis/inspiration for efficient processing multiple of CMD records at the same time.
Caching
The CMD2RDF tool should support caching. As next to conversion also enrichment of the RDF with links into the linked data cloud is envisioned this caching mechanism should be general, i.e., can cache arbitrary HTTP (GET?) requests.
The cache could have a simple API and should be persistent, i.e., on a subsequent run of CMD2RDF the same CMD profiles, components and possibly other web resources should be available. For web resources HTTP caching directives might be obliged, and might indicate a request to refresh the cached resource for this run. Public CMD profiles and component are in principal static. However, from time to time Component Registry administrators do get requests to update, for example, a Concept Link. So the cache might decide to once in a while refresh the cached public profile or component.
Some, if not all, of the conversion and enrichment takes place with the XSLT 2.0 Saxon processor. To keep the XSLT 2.0 stylesheets generic they fetch the CMD profile, component or other web resource using the document() or doc() function. Saxon allows one to register an URLResolver, which can interact with the generic CMD2RDF cache.
The cache of CMD profiles needed by the CMD records also indicates which profiles (and the components they use) should be converted to RDFS. The cache should thus be queryable, i.e., return a list of cached URLs starting with http://catalog.clarin.eu/ds/ComponentRegistry/rest/registry/profiles/.
There is an implementation of cache within the old prototype of MDService2. It was adapted specific to the needs (especially to the REST-interface, i.e. request parameters) of the service, but maybe it can be used as base/inspiration.
Workflow
Conversion and enrichment might involve several steps of different types or purposes:
- XSLT 2.0 transformation
- enrichment by some Java code
- ...
The actions CMD2RDF takes for a record or a profile/component could be configurable. A first sketch:
<CMD2RDF> <config> <!-- some general config: - path to the harvested records - base-uri of the component registry - nr of threads - output directory - Virtuoso or even a general endpoint that supports the Graph Store HTTP protocol (http://www.w3.org/TR/sparql11-http-rdf-update/) - ... --> </config> <record> <action name="transform"> <stylesheet href="CMDRecord2RDF.xsl"> <!-- pass-on the registry defined in the config section above --> <with-param name="registry" select="$registry"/> </stylesheet> </action> <action name="java"> <class name="eu.clarin.cmd2rdf.findOrganisationNames"/> </action> <!-- ... other actions ... --> </record> <profile> <action name="transform"> <stylesheet href="Component2RDF.xsl"> <!-- pass-on the out directory defined in the config section above --> <with-param name="out" select="$out"/> </stylesheet> </action> </profile> <component/> </config>
So CMD2RDF tool would have 3 main phases:
- Process the CMD records (in multiple threads)
- for each record process the actions sequentially, where the output of each action is the input of the next
- the input of the first action should be a CMD record from the OAI harvester result set
- the result of the last action should be RDF XML to be uploaded to the Graph Store
- Process the profiles (as used by the records) (in multiple threads)
- for each profile process the actions sequentially
- the input of the first action is a CMD profile from the CMD2RDF cache
- the result of the last action should be RDF XML to be uploaded to the Graph Store
- Process the components (as used by the profiles) (in multiple threads)
- for each component process the actions sequentially
- the input of the first action is a CMD component from the CMD2RDF cache
- the result of the last action should be RDF XML to be uploaded to the Graph Store
Note: for phase 3 phase 2 could output the components, which might complicated as until now they would just request resources from the cache not store them. Phase 2 could also just request the used components from the Component Registry and thus trigger caching from them. This is some extra load for the Component Registry, but might keep the CMD2RDF caching API simpler.
Types of actions would all implement a common interface so they can be loaded by using the Java Reflection API. Next to the output of the previous action (or the initial CMD resource) they get the XML snippet for the action. Using this info they can configure the action, e.g., load the XSLT or Java class, and execute it.
For inspiration: the OAI harvester allows to configure actions on harvested records, e.g., to convert OLAC to CMDI.
TODO: the harvest isn't incremental, but CMD2RDF could be. It could handle only the delta of a previous run, i.e., convert and enrich new CMD records, convert and enrich updated CMD records, remove graphs for deleted CMD records, the same for profiles and components. MD5 checksums might help to determine if CMD records have been changed ...
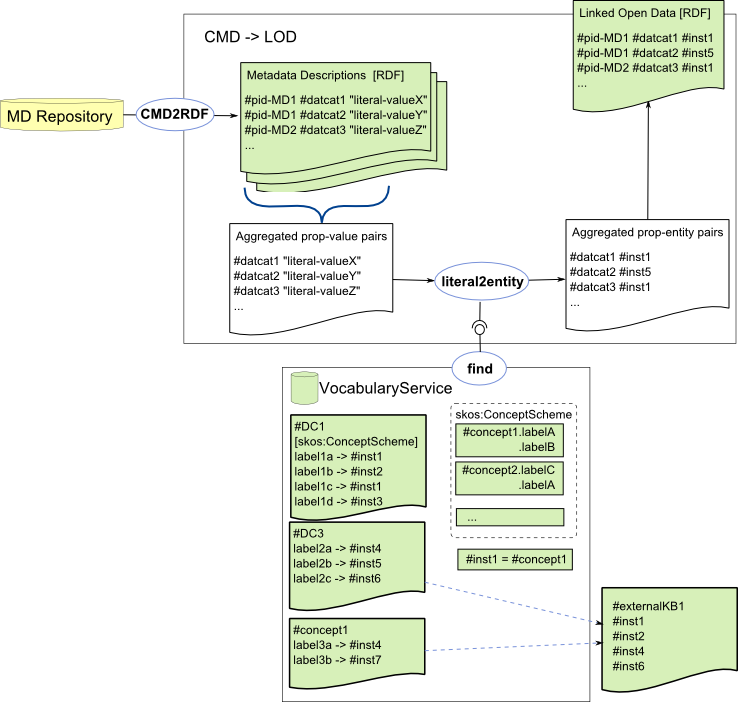
Enrichment - Mapping Field Values to Semantic Entities
The biggest challenge and at the same time the most rewarding/useful step of the process is the resolution of the literal values to resource/entity references (from other/external vocabularies). This is essentially the "linking" step in the "Linked Open Data".
We can identify 5 steps:
- identify appropriate controlled vocabulares for individual metadata fields or data categories (manual task, though see the
@clavas:vocabularyattribute introduced in CMD 1.2 ) - extract distinct
< data category, value >pairs from the metadata records - lookup the individual literal values in given reference data (as indicated by the data category) to retrieve candidate entities, concepts
- assess the reliability of the match
- generate new RDF triples with entity identifiers as object properties
Note: It is important to perform the lookup on aggregated data (< data category, value > pairs), otherwise introducing a huge inefficiency.
Following figure sketches the processing workflow for resolving literal values to entities using a external Vocabulary Service (CLAVAS?) (it originates from the thesis by Durco: SMC4LRT):
")
Modelling issues
In the RDF modelling of the CMD data, we foresee two predicates for every CMD-element, one holding the literal value (e.g. cmd:hasPerson.OrganisationElementValue) and one for the corresponding resolved entity (cmd:hasPerson.OrganisationElementEntity). The triple with literal value is generated during the basic CMDRecord2RDF transformation. The entity predicate has to be generated in a separate action, essentially during the lookup step.
Example of encoding a person's affiliation:
_:org a cmd:Person.Organisation ; cmd:hasPerson.OrganisationElementValue ’MPI’ˆˆxs:string ; cmd:hasPerson.OrganisationElementEntity <http://www.mpi.nl/>. <http://www.mpi.nl/> a cmd:OrganisationElementEntity .
Questions, Issues, Discussion
- Where does the normalization of values come in?
Naturally, the lookup step is a good place to get a normalized value, as the vocabularies used for lookup mostly maintain all the alternative labels for given entity. So one would get the entity reference and the normalized value in one go.
Attachments (2)
- CMD2RDF-sysarch.png (116.0 KB) - added by 10 years ago.
-
SMC_CMD2LOD.png (122.6 KB) - added by 10 years ago.
Sketch of the processing workflow for resolving literal values to entities using a external Vocabulary Service (CLAVAS?)
{kind=link}
{kind=link}
Download all attachments as: .zip