CMDI Metadata Services
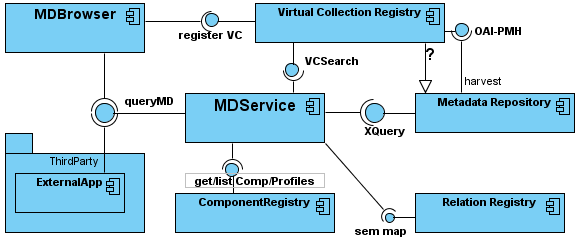
The CmdiMetadataServices component (MDService) is the core component on the consumption side of CMDI.
This page contains the abstract interface specification, there is a special page detailing on the implementation decisions and another one about the tightly related MetadataBrowser.
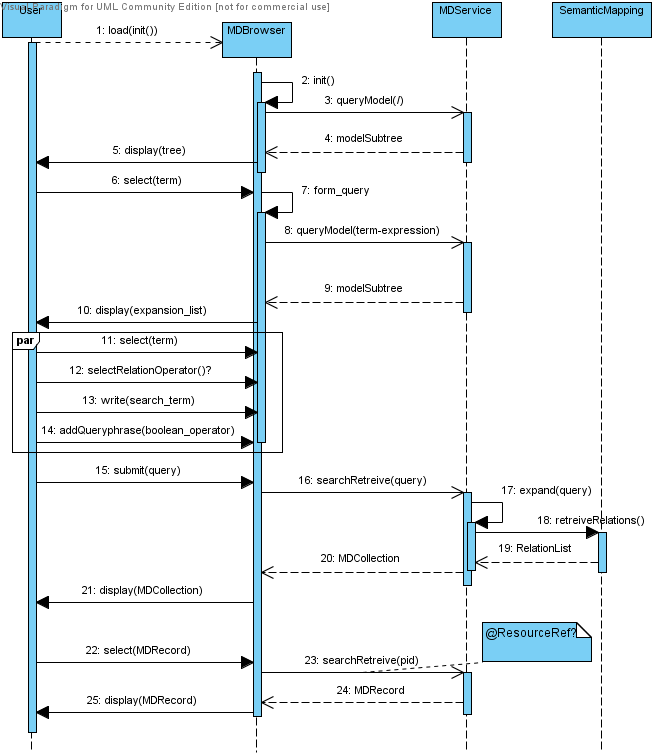
MDService accepts queries about metadata from MetadataBrowser (and external Applications)
- and passes them to the Metadata Repository(ies)
- and/or to the Virtual Collection Registry,
- optionally applying SemanticMapping based on the information from ComponentRegistry, Data Category Registries (isoCAT, dublin core) and Relation Registry
- receiving results and passing them back to the requesting node.

So MDService interacts with:
- MetadataBrowser
as provider - MetadataRepository
as consumer - ComponentRegistry
as consumer - RelationRegistry
as consumer - VirtualCollectionRegistry?
as consumer /provider? - external Applications
as provider; but perhaps also consumer thinkable, when a potential external metadata repository provides a (XML)search interface
The main competencies/tasks/functions are:
- serve MD-Records
-
via browsing/searching
passing the request to MDRepository - provide Vocabularies
-
(out of existing schemas)
for the end-user (and user-agent)
needed to be able to formulate a query. (select lists, catalogue, ..) - translate
-
from Vocabulary-based user query to XPath/XQuery for the MDRepository
(and consequently communicate with MDRepository)
optionally employing semantic mapping involving RelationRegistry
Side note: We could think of subtyping MDService or adding "DataPorts?" which would make MDService more "multilingual", so that it can access different MD Repositories (besides the native CMDI MDRep). So there could be a DataPort? for a RDB based repository (well supported by XQuery) or even for Filesystem based repositories. (Which would come near to LocalWorkspace? functionality. See below.)
Interface Definition
There was a longer development of the interface specification for MDRepository/MDService. There was:
- the initial proposal by Daan (2009-10)
with the operations.elements(), .values(), - 1st version (extension) by Matej
with.listSchemas(), .listDimensions(), .listVocabularies(), .stats(), .countMetadataEntries() ... - "consolidated" version by Matej:
.getCollections(), .queryModel(), .searchRetrieve(query, result_options)
this set of operation is currently implemented by MDRepository - based on the consolidated version a "convenience" interface of MDService evolved with:
.collections(), .model(), .values(), .terms(), .recordset(), .record()
Following table tries to give an overview of correspondence between these and especially also the relation to the actual standard SRU/CQL, we want to conform to:
| Daan | consolidated (MDRepo) | convenience (MDService) | SRU/CQL |
getCollections | collections | (explain, Zeerex)?
| |
elements | queryModel | model, terms | explain
|
values | scanIndex | values | scan
|
searchRetrieve | recordset, record | searchRetrieve
|
With current state of implementation, the "consolidated" interface-version implemented by the MDRepository presents the factual core. MDService builds upon this providing semantically equivalent but richer interface (mainly wrt formatting), which is described in WADL WADL-html
The following subchapters concentrate on the description of the three operations of the "consolidated"-interface, preceded by a chapter about situation and plans regarding SRU/CQL-compliance.
getCollections()- provides information the hierarchical structure the md-records are grouped in.
queryModel()-
provides information about the metadata (meta-model?), ie which components/elements/values are used in the repository. As query-parameter it only needs to accept/understand
cmdIndex. searchRetrieve()-
is the core operation to retrieve the actual MDRecords. In the
query-parameter it has to accept any query on metadata.
Notes on MDService’s SRU/CQL-standard conformance
Although the interface specification was inspired by the SRU/CQL protocol, during the prototyping phase unfortunately an idiosyncratic interface evolved (see "consolidated" and "convenience" mentions above), MDRepository and MDService currently exposing their own set of operations. Thus at the moment MDService can’t claim conformance with SRU/CQL standard.
However we are still committed to this goal and we have substantial partial solutions: MDService accepts the query in CQL-format (even parsing it, ensuring the syntactic validity) and returns a <searchRetrieveResponse> result as defined by the protocol.
An example: title contains system in MDService
The result comes in the standard-compliant format already from MDRepository, which however expects the query in XPath and there is also no plan for the MDRepository to accept SRU/CQL-queries, thus MDRepository is not to be expected SRU-conformant.
The main missing part is the appropriate REST-interface accepting the defined parameters. As MDservice exposes this own set of operation optimized mainly for the use by the web-application (MDBrowser), the plan is to provide an additional separate interface exposing the SRU-operations, mapping these operations internally to appropriate processing.
getCollections()
Rough equivalent of OAI-PMH's listSets. Lists collections-tree. This information is needed especially by the other interfaces, that take collection as constraining parameter. See also #1.
queryModel()
This interface provides information about the metadata (meta-model?), ie which components/elements/values are used in the repository (+ the counts). For this it should merge together the information on the CMD_Components and CMD_Elements as defined in the ComponentRegistry with the real data from the MDRepository.
Provided with a component path it returns applicable elements or values in given context, e.g.:
/Actor/Contact => [Name,Address,Organization,...]
Language => {List of Languages}
- request-pattern
-
http://mdservice/queryModel?q[collection=all|format=xml|maxdepth=1] http://mdservice?operation=queryModel&q[collection|format|maxdepth]
- parameters
| param | value | description |
| q | cmdIndex as defined in QueryLanguage | provides context from where the result-tree shall start |
| collection | identifier of one (or multiple) collection(s) default:=all | constrains the query to a specific selection of collections to provide the model for |
| format | [list|xml|json|html?] default:=xml | format of the result |
| maxdepth | positive integer (probably restricted on the server side to some reasonable allowed maximum); default:=1 | the desired of the depth of the model subtree |
Result format
The returned values are:
| value | xml encoding | format |
| component/element id | Term@cid | uri |
| component/element name | Term@name | componentName |
| component/element path | Term@path | cmdIndex or XPath ? |
| count element in the repository | Term@count | posInteger |
| count element with text | Term@count_text | posInteger |
| count distinct values in given element | Term@count_distinct | posInteger |
| distinct values in given element | Term/Value | string |
| count number of uses of given values in given element | Term/Value@count | string |
In general the result can be a subtree of the model of arbitrary depth.
Depending on the maxdepth-parameter it returns either simple lists, or whole model subtree. In the interaction with MDBrowser this could mean:
- model subtree in the initialization phase
- simple list during query-building (has to be fast!)
Examples for a simple list result:
request:
http://mdservice/queryModel?q=MDGroup.Actors.Actor
(defaults: collection=all, format=xml, maxdepth=1)
result:
<Term id="clarin.eu:2626" name="Role" path="//MDGroup/Actors/Actor/Role"
count="14500" count_text="13700" count_distinct="14" />
<Term id="clarin.eu:2627" name="Name" path="//MDGroup/Actors/Actor/Name"
count="14500" count_text="14200" count_distinct="14180" />
request:
http://mdservice/queryModel?q=Sex
result:
<Term id="" name="Sex" path="" count="14500" count_text="14500" count_distinct="2" >
<Value name="Unspecified" count="1500" />
<Value name="Unknown" count="13000" />
</Term>
Example for a model subtree :
request:
http://mdservice/queryModel?q=MDGroup.Actors.Actor&maxdepth=3
result:
<Term id="" name="Actor" path="//MDGroup/Actors/Actor" count="14500" count-count_distinct="9200" >
<Term id="" name="Contact" path="//MDGroup/Actors/Actor/Contact" count="13700" count_distinct="12000" >
<Term id="" name="Address" path="" count="300" count_textcount_distinct="300" />
</Term>
<Term id="" name="Role" path="" count="9900" count_text="1347" count_distinct="20" />
<Term id="" name="Sex" path="" count="14500" count_text="14500" count_distinct="2" >
<Value count="1500" >Unspecified</Value>
<Value count="13000" >Unknown</Value>
</Term>
</Term>
Probably a (one or multiple) initial model should be defined/constructed, a default set which balances size of the data and information content by providing the most relevant elements to have a rich, but no too big starting point for the searches.
Ideas for elements to be included in this default set:
- Language (Country)
- Institute,Project
- Type/Modality?
- Accessibility - this is problematic - it may in many cases not be determinable by MD alone (special AAI policies managed by Content Provider etc.); but nevertheless some rough indication should be available!
- Scope|coverage (/Time,Space,Genre)
searchRetrieve()
Core interface retrieving the actual MDRecords based on a query. This is meant to be compatible to the searchRetrieve operation of SRU/CQL
- request-pattern
-
http://cmdrepository/rest/mdservice?operation=searchRetrieve&[query|version|...]
- parameters
| param | value | description |
| query | extended CQL as defined in QueryLanguage | the whole query |
| {all the params defined in SRU} | consult SRU specification | |
| (collection) | [0..*] collection-identifiers | this shall also be encoded in the query, not as separate parameter |
Result format
SRU also defines the format of the result, distinguishing:
- Response Parameters
- Record Parameters
- Record Packing - Result Sets
The parameters (encoded as elements in the xml response) handle just generic information and also provide wrappers for the actual "record data" (recordData, extraRecordData), where our CMD records should fit in.
One could argue Which information (from the individual MD-Records) shall be included in the Result set has to be sorted out yet, but although it may be certain waste of bandwith to send around whole MD-Records, it saves additional processing, and allows for richer manipulation nearer to the client. (If the user wants to see more field, a full request to MDRepository would not be necessary, as the whole MD-Records would reside either in the session-cache of MDService or MDBrowser.)
SRU foresees the request parameters: recordSchema, stylesheet to be used by the client to influence the format of the result.
optional/questionable Interfaces
A further experimental interface would be:
searchByExample (Collection[MD-Entries])
=> Collection[MD-Entries]
Based on provided MD-Entries try to find similar
this would require sophisticated processing:
- identifying set of relevant terms
- possibly provide the identified terms to the user, for priority ordering
- adaptive search based on these terms, loosening or tightening the criteria depending on the size of the result-set
An optional separate interface for publishing Resources (not the OAI-PMH way):
.publishResource(MD) -> MDRep.registerResource() | VCR.registerResource()
Relevant resources could be
- VirtualCollections?,
- user's "private" Resources she wants to share or
- new Resources as results of processing existing ones.
It is questionable, if this should be the competency of MDService/MDBrowser in general.
But regarding the VirtualCollections? MetadataBrowser will be the natural place for creating them (as result of MD search). (see there for more details)
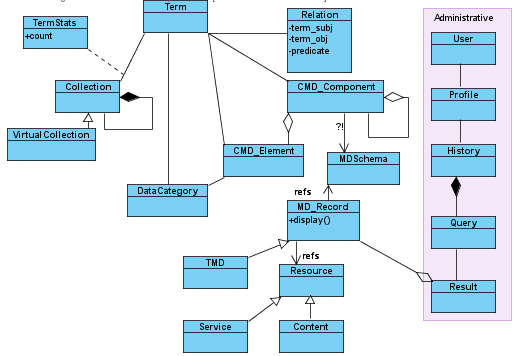
Domain Model

Following a class diagram of the domain model (business objects) planned for MDService. Generally it is the entities being carried in the various XML-Streams, which rather sooner than later MDService, needs to be made aware of (JAXB - as the technology of choice for transforming between XML and Java-objects), to be able to do some sophisticated stuff with it. A few remarks on this:
- Term
-
a special class is proposed, that would abstract from the specifics of the classes from registries:
CMD_Component,CMD_Element,DataCategory. It is not a superclass, but rather a special class, that models the dependencies between the other classes / datatypes mentioned. - Collection
- the basic hierarchical structure in which the MD-Records are organized A query without specified collection is evaluated against whole Repository (all collections)
- Terms vs. Collection
-
In every query, or generally for any viewing of the MDRepository we have to be aware at least of the two dimensions: Terms (all the existing MD-Elements) and Collections.
This is especially important for any statistics for individual Terms (
TermStats), they always have to be provided in the defined collection-context (all collections by default?) - Virtual Collection
- From MDService point of view Virtual Collection is a subclass of Collection, meaning it can be handled as Collection. The distinction is, that it may come from other source (VCR - see discussion under: MetadataBrowser#VirtualCollection), and has some other specifics (user-specific, user can create).
- Query
- the "basic unit" modelling one user-request.
- QuerySet?
- a collection of Queries.
- History
- a subclass of QuerySet?, collecting all queries submitted byt the user.
AAI
Access to the Metadata has to be open, thus no AAI necessary here. On the other hand modelling user allows for extended features, so we plan optional login, following the common approach adopted in CMDI as whole.
Attachments (3)
- interaction_MDBrowser_MDService.png (28.2 KB) - added by 14 years ago.
- MDServices_only.png (21.7 KB) - added by 14 years ago.
-
MDService_model_classes.png (20.9 KB) - added by 14 years ago.
Class Diagram of the planned model for MDService
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip