Introduction
The CLARIN metadata infrastructure (CMDI) describes a model to specify collections of resources [1]. The basis of CLARIN collection specification is that we can use a metadata description as the incarnation of a collection. That metadata description should then serve as an interface through which all collection wide operations are performed on the collection’s resources.
This together with the CLARIN metadata model itself offers a number of options:
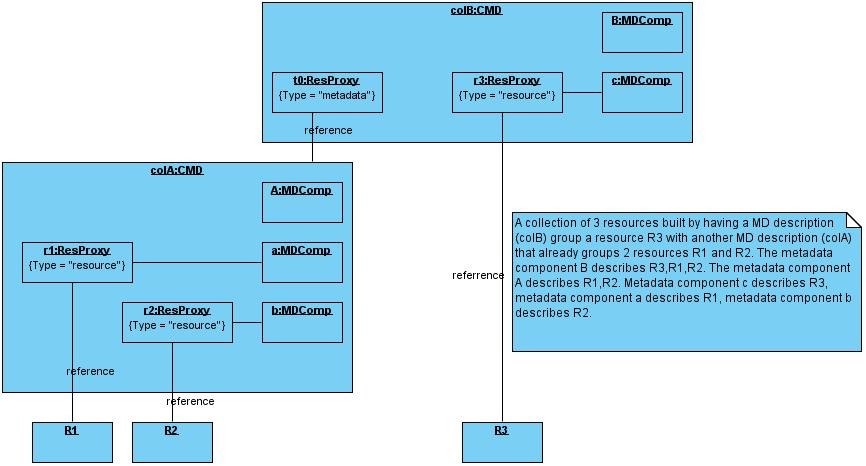
- 1 Have a metadata description that points directly to all resources of the collection.
- 2 Have a metadata description that points to other metadata descriptions that point either to another metadata description or to a resource.
- 3 Have a combination of 1 and 2. (see Figure 1.)
All three options are permissible and have each their specific advantages in different use cases. We should however try to identify “core” metadata that is essential for the collection metadata to function within different CLARIN usage scenarios. Therefore we will first now describe the different use cases that have been identified by the CLARIN community.

Usage of CLARIN collection metadata
Currently we have identified the following cases:
- 1. Unique identification of collections
- 2. Registry of collections for future use
- 3. Citation & reference of collections
- 4. Searching for relevant collections
- 5. Browsing the internal collection structure
- 6. Extension & modification of collections
- 7. Obtaining access permission for all the collection’s resources or reporting where access permissions are not (automatically) available.
- 8. Usage of collections in workflow scenarios
- Unique identification of collections
This depends on the adoption of a suitable identifier scheme that guaranties uniqueness and also on embedding the identifier in the collection metadata description. CLARIN accepts suitable identifier scheme for resources and metadata are described in “Persistent and Unique Identifiers” (http://www.clarin.eu/files/wg2-2-pid-doc-v4.pdf) . It should be emphasized that also suitable stable URIs (Cool URIs) are permissible, however special services that may be developed on the basis of PID systems will not be available for these. OAI identifiers from the OAI header in OAI records should not be accepted, they are useful for harvesting metadata and usually the OAI identifier maps on a (persistent) identifier from another more suitable identifier scheme but that cannot be relied upon. For the sake of coherence we should require a suitable identifier being available in an <Identifier> element of the collection metadata itself. It is important to notice that for collections the identifier is interpreted as identifying the collection.
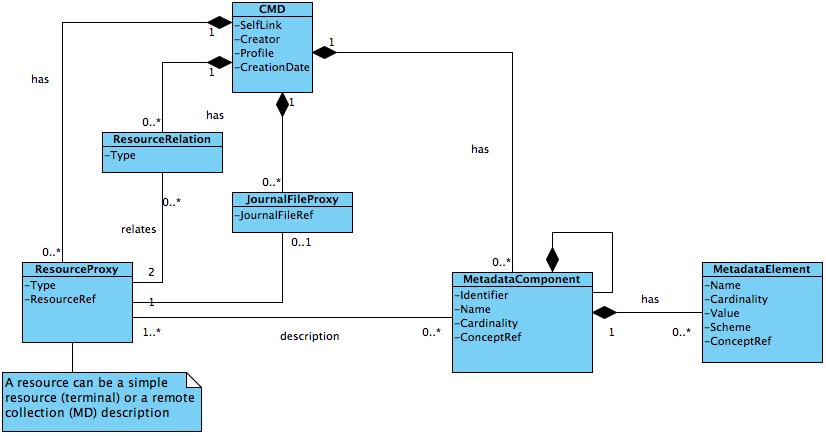
2 Registry of collection metadata Collections may result from search or browsing actions making them virtual collections (VC) rather than intended “published” collections. These VCs however may be required to be citable for future use. CLARIN therefore stated its intention to provide a registry for such collections, allowing researchers to store VC descriptions that can be referred to from documents or other resources. Such registries do not impose special requirements other than the registries should be persistent, and that the collection metadata should, for administrative reasons, be able to identify the registry. Depending on the usage of the collection provenance or journaling information how the collection came into existence can be required. This is already foreseen in the basic CLARIN component metadata model, see the JournalFileProxy? element in Figure 4 of [1].

- Citation and referencing Collections
First of course a persistent identifier is required that references the collection’s metadata. PID For citation purposes it seems suitable to have metadata that describes purpose of the collection and identifies who is responsible for the creation and registration (of the collection description, not the resources themselves).
- Metadata search.
Because VCs are “derived” collections and are of a different importance than published corpora (metadata is created by the resource providers), it should be possible to filter out the VCs from metadata search. So VCs should be recognizable as such (VC flag). But when purposefully searching for suitable VCs we need the possibility to search on “purpose” and “creator”. A suitable “purpose” vocabulary should be investigated.
We can expect that intended published collections
- Browsing the internal collection structure.
This implicates both VC and published collection metadata. The CLARIN metadata component model supports browsing the internal structure (corpus – subcorpus hierarchies), no special metadata is needed. However browsing tools should be aware of this and enable descending into this structure and enable display of further layers of metadata.
- Extension & modification of collections
This point is very much connected to the versioning policy that the collection’s resources providers implement. If a resource in a VC is modified without issuing a new PID, the VC’s PID will inherit the same versioning policy. It becomes worse if the VC contains resources from providers with different versioning policies. It should be made explicit from the VC metadata what versioning policy for the VC results. A suitable vocabulary for a versioning policy metadata field should be proposed.
- Authorization issues
It is important that a user of a VC or published collection is able to determine if he has access to all resources and if not, what procedure should be followed to make a request for access. For individual resources and published collection we already have a “strongly recommended” metadata component [1] with such information. A VC registry tool should exploit that information and inform a VC’s prospective user about current access status and the possible steps to take to obtain access.
- CLARIN workflow
In order to create interoperability with CLARIN workflow mechanisms collection metadata should (1) allow extension with processing results (bundle concept in [1]) and (2) allow processing modules to analyze the collection and obtain the individual resources and the resource’s technical metadata necessary for establishing suitability and processing. The intrinsic model satisfies both requirements provided every individual resource is covered by the metadata.
Building the collections hiearchy
This is a summary of issues encountered when processing the test-dataset on eXist. So it is data- and implementation-specific.
Although the test-dataset is structured in folders and similarily will the dataset harvested via OAI be structured in sets,
we need ot establish the collection hierarchy based on the ResourceRef-linkage inside the individual records (as suggested above).
Naturally the two hierarchies will be similar, but there seem no safe assumption possible regarding the relation between the two, thus we have to ignore the implicit folder-structure altogether. Thus we have to build up the structure from individual records, each having only the information about it's children,
not even knowing which records are on the top-level (not part of any other collection.)
We applied following algorithm to resolve the hierarchy:
- add reverse link
- loop through all records with
Metadata-ResourceProxy - traverse the
ResourceProxy/ResourceRef-links to reach the individual children - in every child add
IsPartOf-element with the identifier of the parent (MdSelfLink) as the value
- loop through all records with
- resolve the whole hierarchy
- find records without
IsPartOf-elements (orIsPartOf='root') - recursively traverse the children-elements (together with passing the collection-ids of all ancestors as parameter)
- in every child add
IsPartOfentries with collection-ids for every ancestor
- find records without
This allows for fast search for records within individual collections (irrespective of the hiearchy-depth).
The question is open yet, if this helps to solve the problem of "hierarchical search", ie search where some of the conditions apply on individual record level and some at the collection-level.
Also the question is not completely solved about identifying the collections. Currently we use the handles in MdSelfLinks, which were replaced with collection-paths where the handles were missing or not unique. This is not very satisfying as the handles are meaningless and bulky. The collection-paths are meaningful but still bulky, but mainly they are just a temporary workaround around the missing handles. They are probably not usable in production as they are derived from the implicit folder hierarchy, which is confusing. Of course the user is presented with the names, which are then translated to IDs, but the question, if it wouldn't be possible to define meaningful identifiers for the collections (e.g. domain-names-like).
mpi:dobes:1 clarin-at:aac-test-corpus:sozialismus:1
Howto search in Virtual Collections
The next problem is how to implement the search in Virtual Collections.
As in general the Virtual Collection can be collection of any MDRecords, for further search in this collection, the whole list of identifiers would have to be sent to MDRepository to be applied as filter on the query. This seems very inefficient and for big collections probably not workable at all. (This is in the context of the basic setup, where the user defines his VC in MDBrowser (and publishes it to VCR) and wants to continue with querying this VC. Thus only MDBrowser/MDService know about both the query and the VC.)
Proposed solutions:
- Virtual Collection is in the MDRepository
-
It is actually planned to harvest the VCR by MDRepository, so eventually all VCs should end up in the Repository..
Then it has to be decided if they will be processed as normal collection (resolving to IsPartOf?-relation - see above), or if they are handled separately, applying them as filter on the fly (filtering the result of the actual query, before sending the final result)
The problem is the harvesting-latency. - POST the VC to MDRepository
- To bridge the harvesting latency, we could think of POST-ing the VC to the MDRepository, when it's not yet inside, so that it can use it for efficient filtering of the actual query. This would require special interface on MDRepository
- Apply VC afterwards
- In this variant MDRepository could be agnostic of VCs. It would just run the query. MDService would fetch the VirtualCollection? and apply it as filter on the result of the MDRepository-query. Obviously this smells like huge waste of bandwidth.
- Query-based or Dynamic Virtual Collection
- If the VC is defined by means of a MD-query, it could be easily used for further constrained search, simply by combining the query defining the VC and the specific user-query. This seems a nice alternative, which would speak strongly in favour of dynamic VCs, which - by consequence - should be encouraged.
Attachments (2)
- collection.jpg (47.9 KB) - added by 15 years ago.
- Metadata Description.jpg (35.7 KB) - added by 15 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip