| Version 13 (modified by , 9 years ago) (diff) |
|---|
VLO/CMDI data workflow framework
Note: The same content is also available at GoogleDoc? https://docs.google.com/document/d/1OoxDEFoZKhmotk7tbrElqcn79acKnj4T897sNctMYH8/edit?usp=sharing Some images are omitted, as they are too big to fit. It is encouraged to read in the GoogleDocs? for the most up-to-date and comprehensive information.
Introduction
This page will outline the VLO data workflow, starting from the current to the future. It divides the possible timeline of the development into three phases for consulting purposes. The phases are best understood by each figure: figure 1 - Current, figure 2 - Phase I, figure 3 - Phase II, and figure 4 - Phase III, which is provided with the ideas of functionalities.
It seems that the individual software projects (OAI harvester, curation module, Component Registry etc) could fit well into this big picture, especially the Dashboard section of Phase II onward.
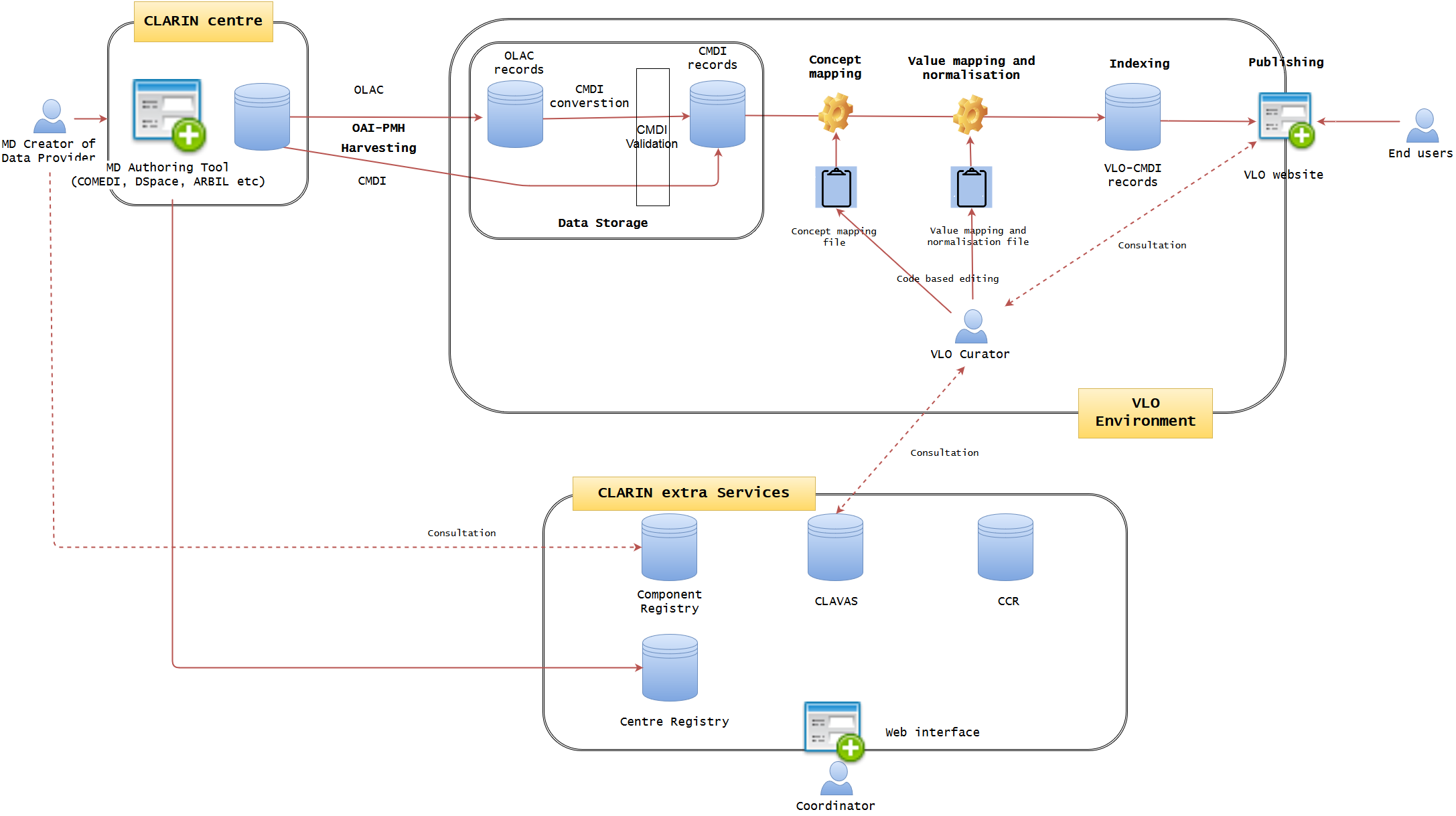
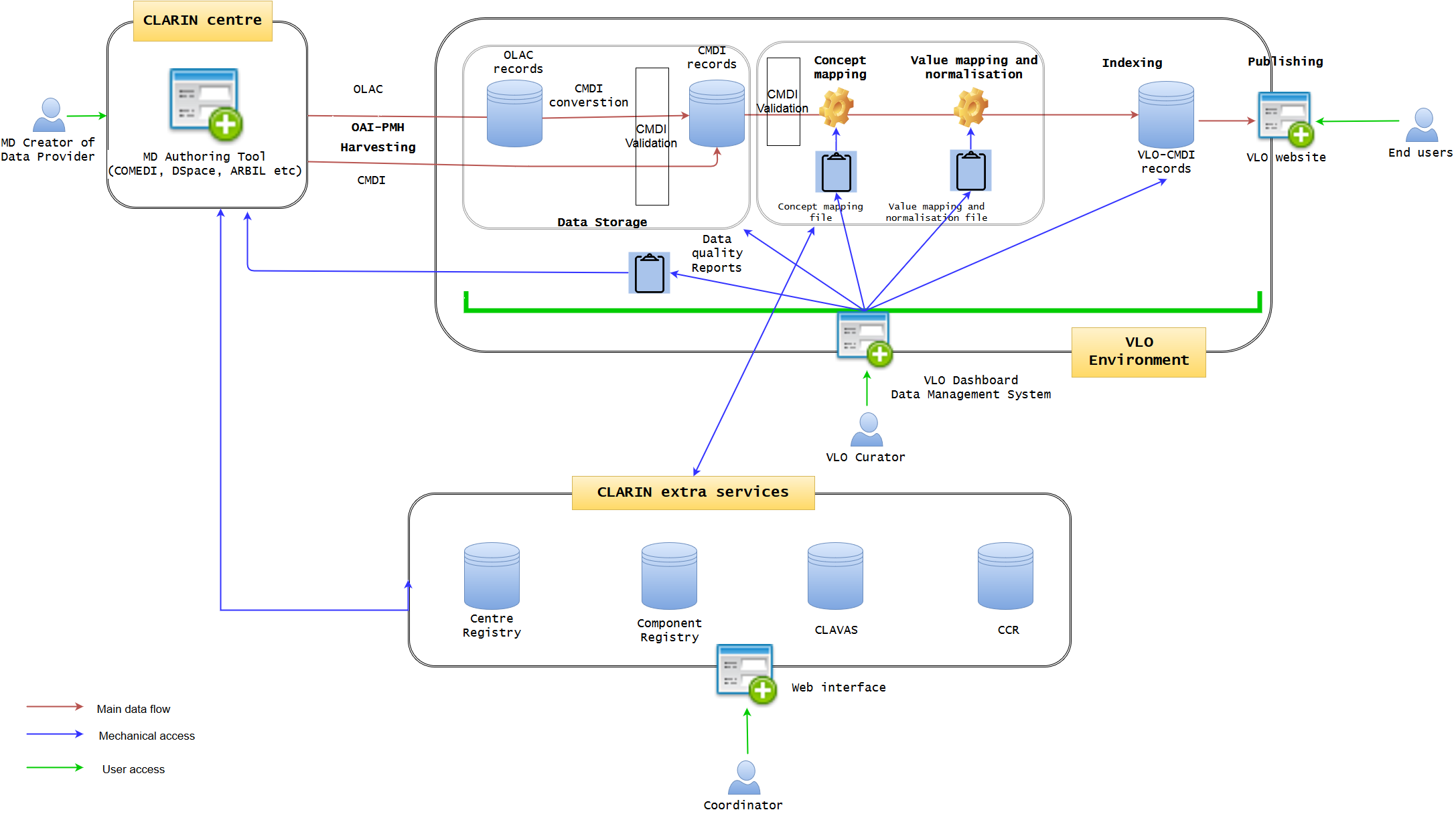
Current VLO data workflow
(may not be accurate. to be precisely produced soon)

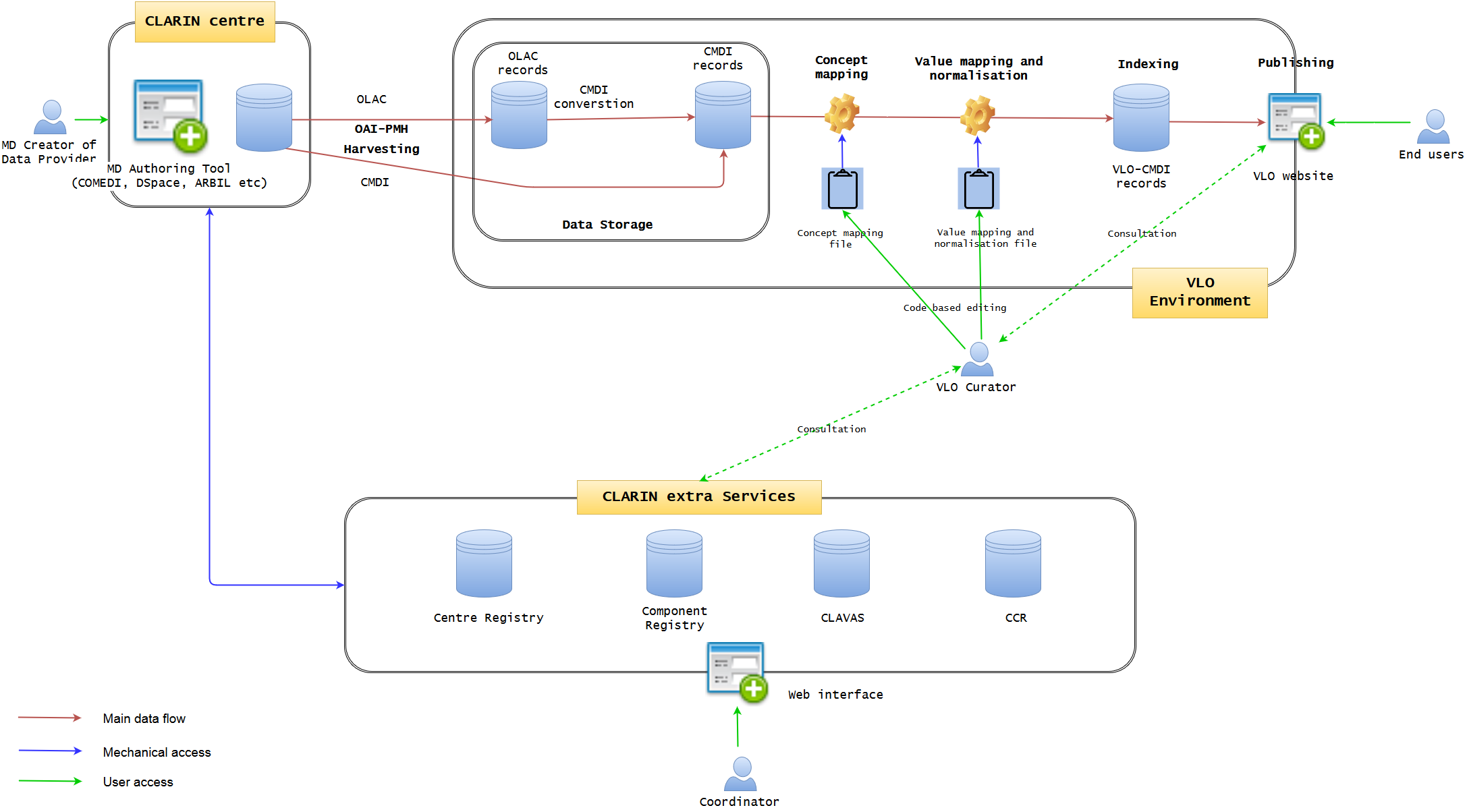
Figure 1 illustrates the current state of data workflow. (It may not be 100% accurate, but will be modified later, if needed) It is well established, but not optimised. A data provider may use a metadata authoring tool hosted at one of the CLARIN centres. The typical examples are ARBIL in the Netherlands, COMEDI developed in Norway and the submission form of DSpace as developed in Czech. It provides an easy-to-use GUI web interface where a CMDI profile can be imported or generated and metadata records can be created. Each of the tools more less tightly integrates with the underlying repository, where the metadata is stored together with the actual resources in one digital object. The metadata is exposed via an OAI-PMH endpoint from where it is fetched by VLO harvester on a regular basis. However, while the authoring tools try to provide a local control over the quality of the metadata (offering custom auto-complete functionality and various consistency checks), a common, formal and rigorous mechanism is lacking for the authoring tools to control the quality of metadata which VLO team is struggling to cope with. The ability of these applications is limited to synchronise and interoperate with four extra CLARIN services, namely Centre Registry, Component Registry, CLAVAS, and CCR. In particular, CLAVAS is not used as authoritative source of controlled vocabularies. At the moment, the data providers are required to make some effort to improve the metadata quality by consultation.
OLAC and CMDI are the two formats allowed to be imported into VLO environment, and the former is converted to CMDI by a predefined mapping. When CMDI is ready, it is being ingested into the solr/lucene index, governed by a set of configuration files: facetConcepts.xml dealing with the mapping of elements to facets (via concepts) and a set of text files defining the normalisation of values. These files are the essence of the CMDI-VLO facet mapping, and, in principle, edited manually by the VLO curators. The processed data will be indexed and published seamlessly on the VLO website, where the end users can browse and search data. The VLO curators also have some difficult time to control the data quality, because they have to manually edit raw files (XML or CSV alike) of concept mapping and value mapping and normalisation, in conjunction with the external CLARIN services. They also need to examine the outcomes on the public website to check the data integrity.
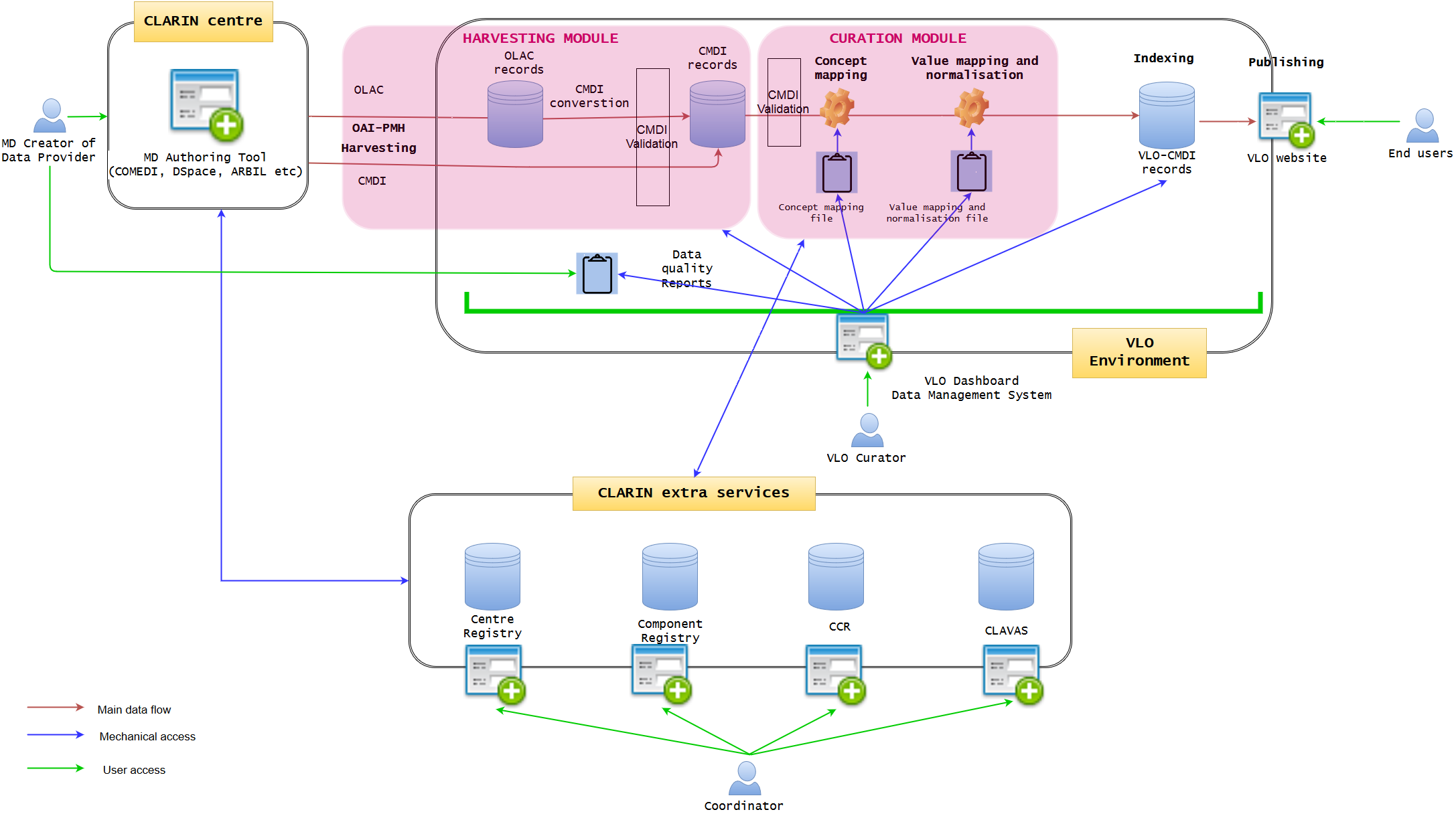
Phase I - VLO Dashboard data management system and extended CLARIN centre MD authoring tool
VLO Dashboard will manage the whole data ingestion and publication pipeline, communicating with extra CLARIN services. MD authoring tool will connect to the extra CLARIN services

In this phase, the main tasks are to develop 1) VLO Dashboard data management system and 2) enhanced MD authoring tool. In terms of implementation, it seems most natural to ask VLO central developers to work on 1) and CLARIN centers to work on 2), simply due to the current responsibilities of the local and central development, so that the two can be developed in parallel, if doable.
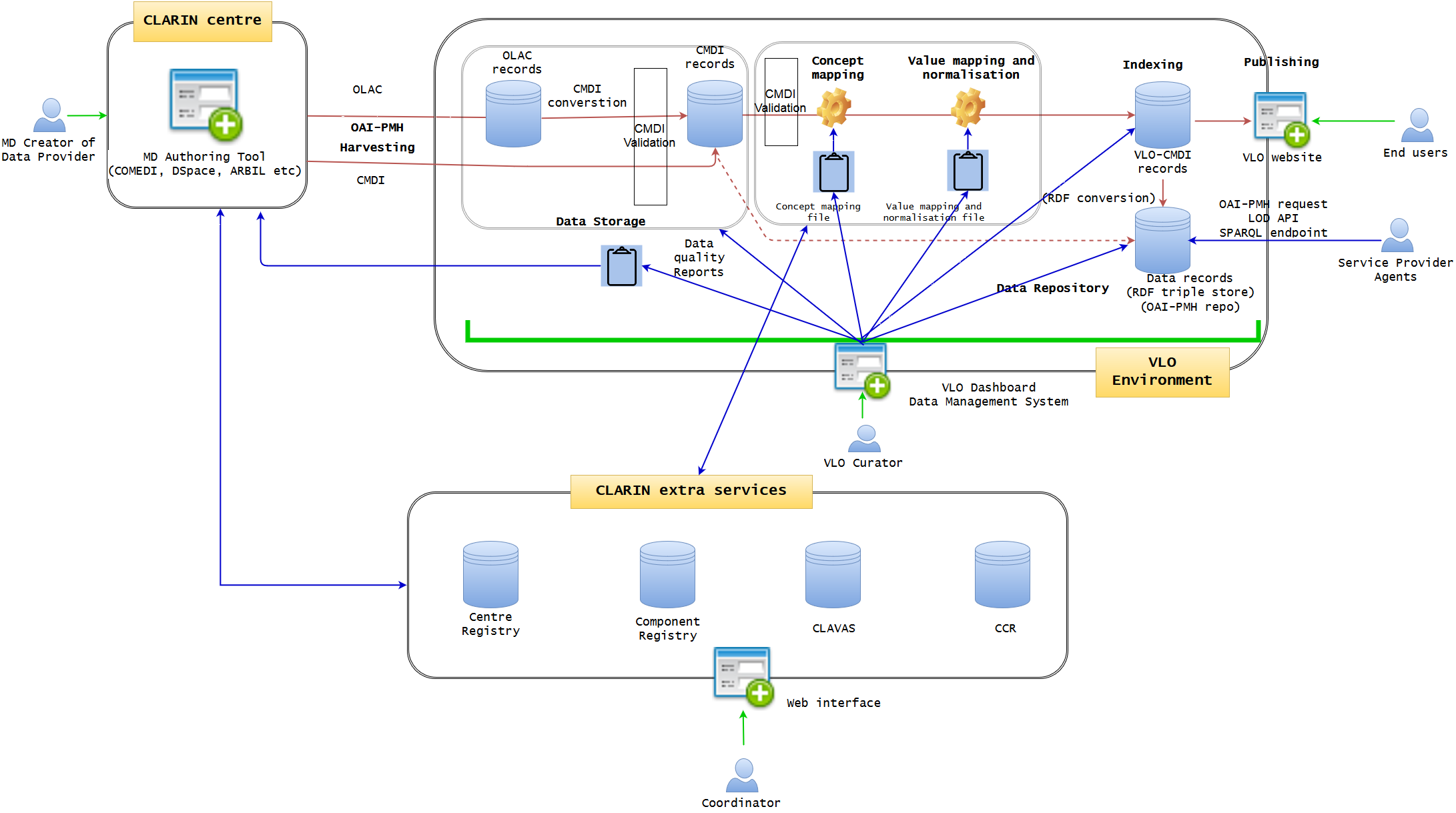
The dashboard is the key development of the core VLO framework. It will integrate all the data ingestion pipeline into one, creating a user-friendly GUI web interface with which VLO curator can work on data management much more efficiently and coherently in a uniform manner. Data integrity will be much more guaranteed within the complex data life cycle of VLO in one environment. The Dashboard approach is based on the well-known OAIS model, encompassing the three information packages: Submission Information Package (SIP), Archival Information Package (AIP), and Dissemination Information Package (DIP). It offers a very intuitive data management view, illustrating the step-by-step process of the entire data life cycle, starting from harvesting, converting, and validating, to indexing and distributing. Those who have no strong technical skill should be able to use it in a similar way to organise a mailbox of an email software. The functionalities should include (but not limited to):
- List of the datasets (OAI-PMH sets) bundled per data provider and per CLARIN centres/countries (MUST)
- Status and statistics of the sets within the ingestion pipeline (errors, progress indicator) (MUST) (export as PDF, XML, CSV etc (SHOULD))
- Simple visualisation of the statistics 2), including pie charts, bar charts etc (CLOUD)
- Browse the data quality reports per set (MUST) (export as PDF, XML, CSV etc (SHOULD))
- Send email of the data quality report to a data provider/CLARIN centre (SHOULD) (automatic email (COULD))
- Edit the concept mapping (MUST)
- Edit the value mapping and normalisation (MUST)
- Manual data management (deactivate indexing of the sets, delete the data sets, harvesting of data sets) (MUST)
- Synchronise the component registry, CLAVAS, and CCR with the data sets (MUST)
- Browse the log files of the VLO systems (COULD)
- Browse the Puwik web traffic monitoring (COULD) (do it per data set (CLOUD))
- Link checker which lists broken links (per set) (COULD)
The next figure is created to visualise the idea of Dashboard in which the VLO curators can monitor the whole ingestion process at one glance. OAI-PMH data sets are listed as rows, and can be easily categorised per country and data provider. Following the ID and title, there is a date of latest update (which can be harvesting date or latest actions). The status of data processing is clearly visible with green and red circles (harvesting, converted to CMDI, validated against CMDI). When it is indexed and published, the number of records are shown. When the data is distributed in a repository (eg OAI-PMH, LOD etc), it is also indicated. The last, but not least, the data quality is provided with the indication by stars. Different actions will be selectable, according to the status of the data. Some ideas of the actions are:
- (Re-)harvesting of the data set
- Disable indexing
- Delete the data set
- Show the data quality report (various statistics e.g mapping coverage, facet coverage, controlled vocabulary coverage, broken links etc)(download them as PDF, CSV, etc)
- Show the error messages (download them as PDF etc)
- Show the metadata sets
- Show the schema/profile (with the link to Component Registry, CLAVAS, and CCR)
- Send an email to the data provider (eg data quality report)

As well as the single data set actions, there will be batch processing options. The users can search, sort, and filter the data in this table view. In addition, s/he can select multiple data sets by clicking the checkboxes on the left. With this table view, the user should be able to see the overall statistics (and/or selected data sets), including the number of datasets, countries, data providers, the status, the number of records indexed and distributed. Those figures are extremely important for the performance indicators (for CLARIN board etc). The user should also be able to export the statistics as PDF and CSV or directly into Google Spreadsheet (this is useful to work with internet traffic statistics of Google Analytics or Piwik).
Be aware that the Dashboard will provide manual data processing functions, but it is just a complementary service of the automatic data processing (as it is currently implemented). It will serve as a very important support for the automatic processing, because the VLO curators can monitor the data and manually interact with it without any knowledge of behind-the-scene codes and scripts, whenever it is needed.
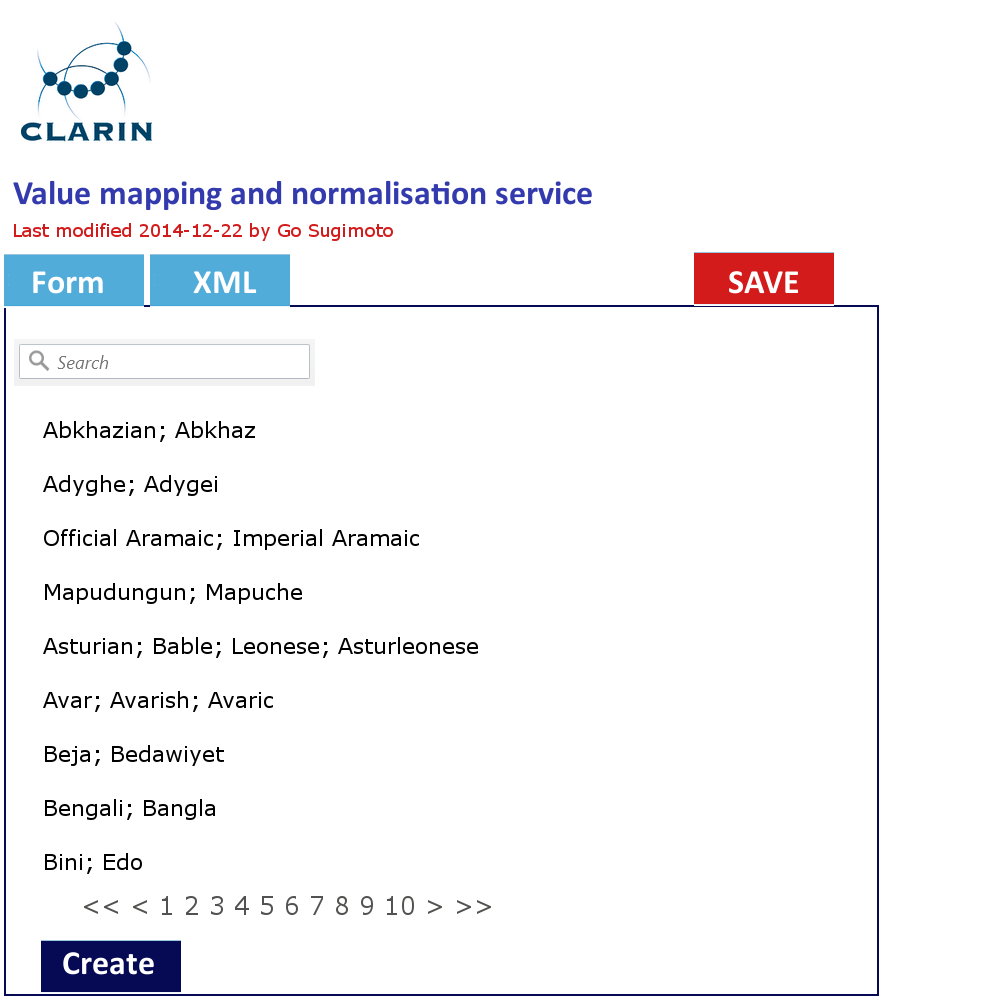
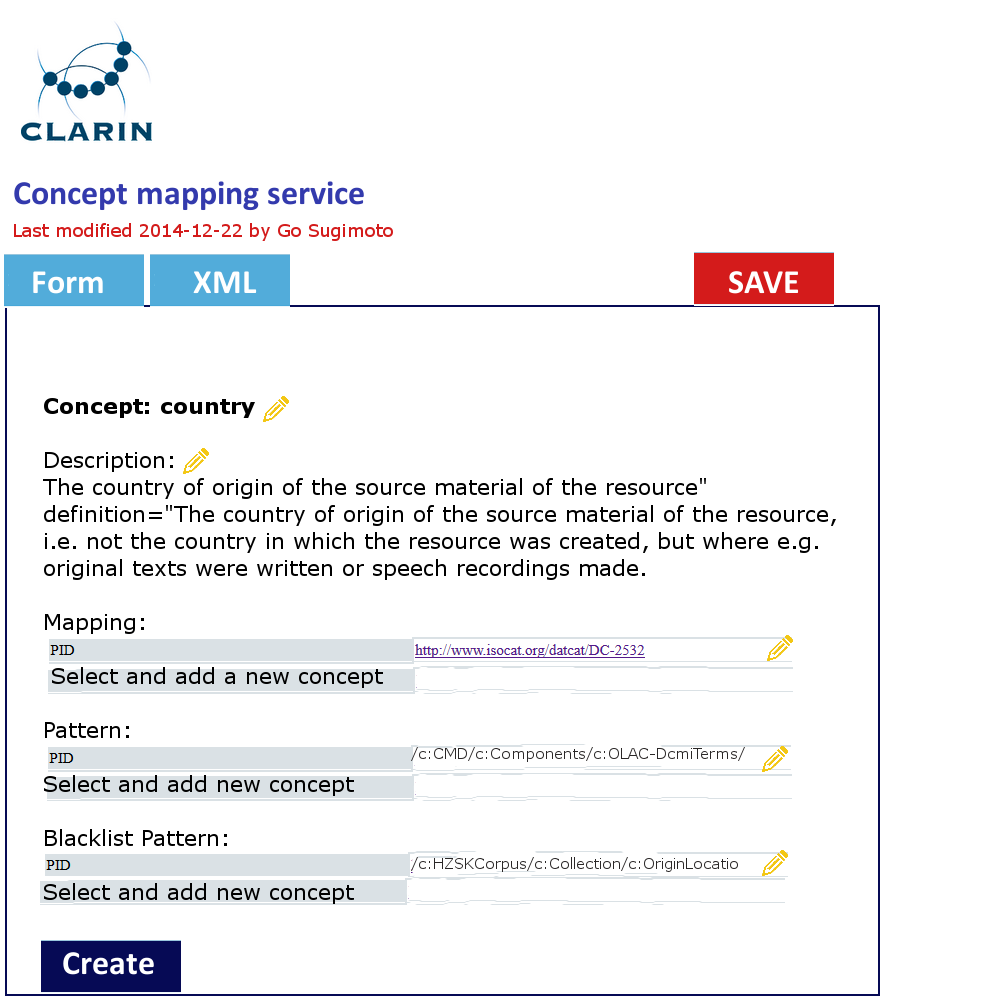
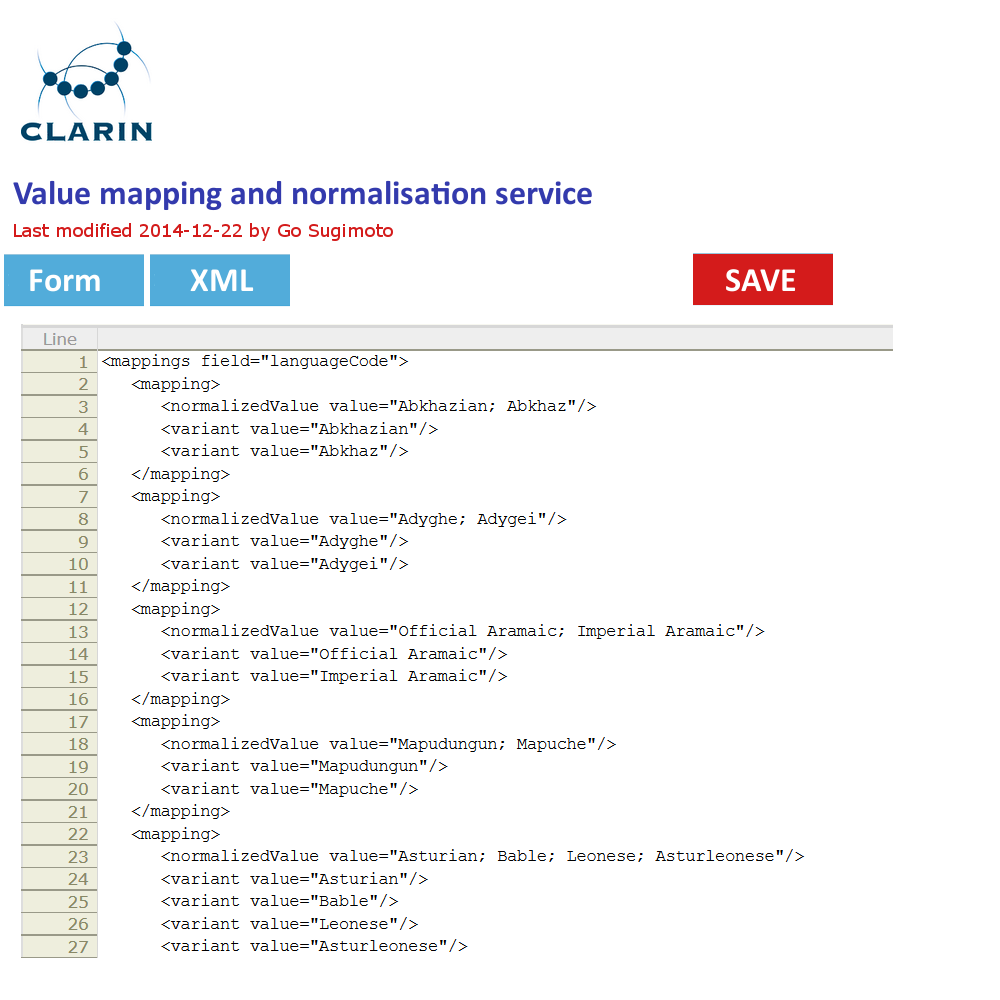
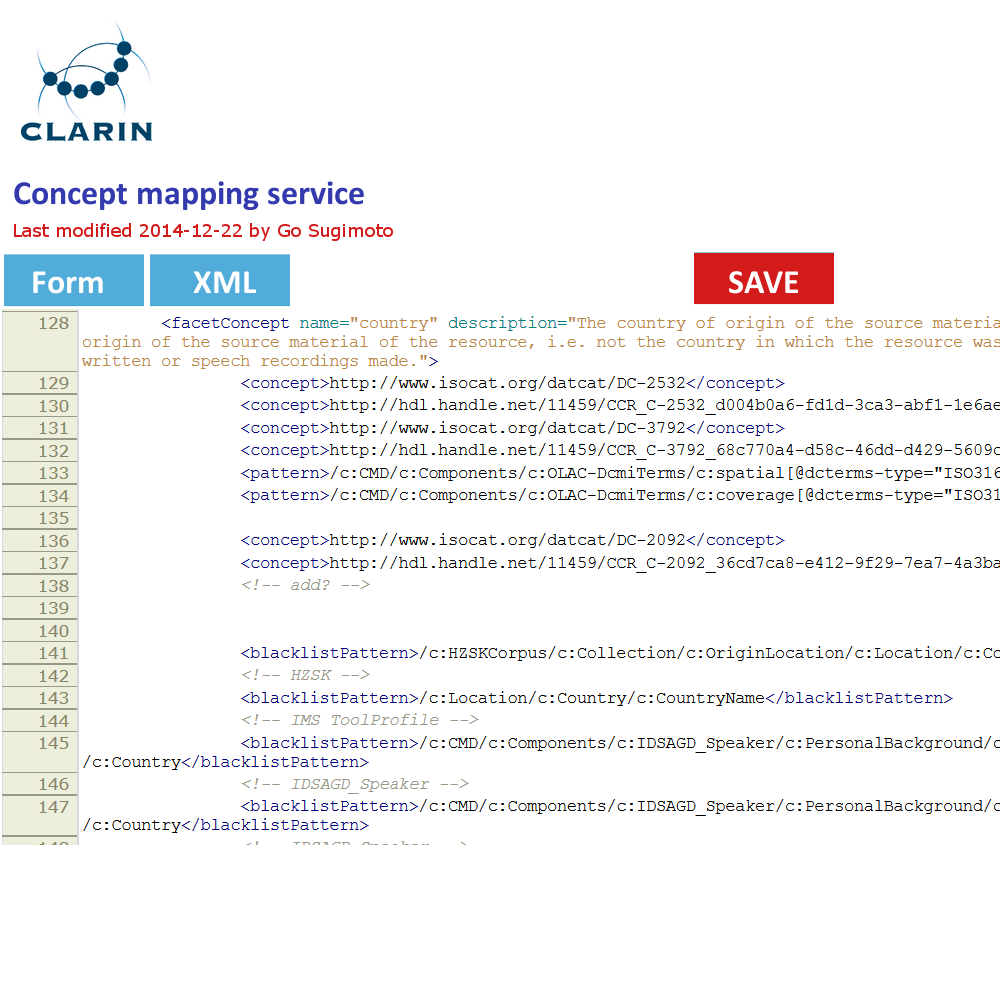
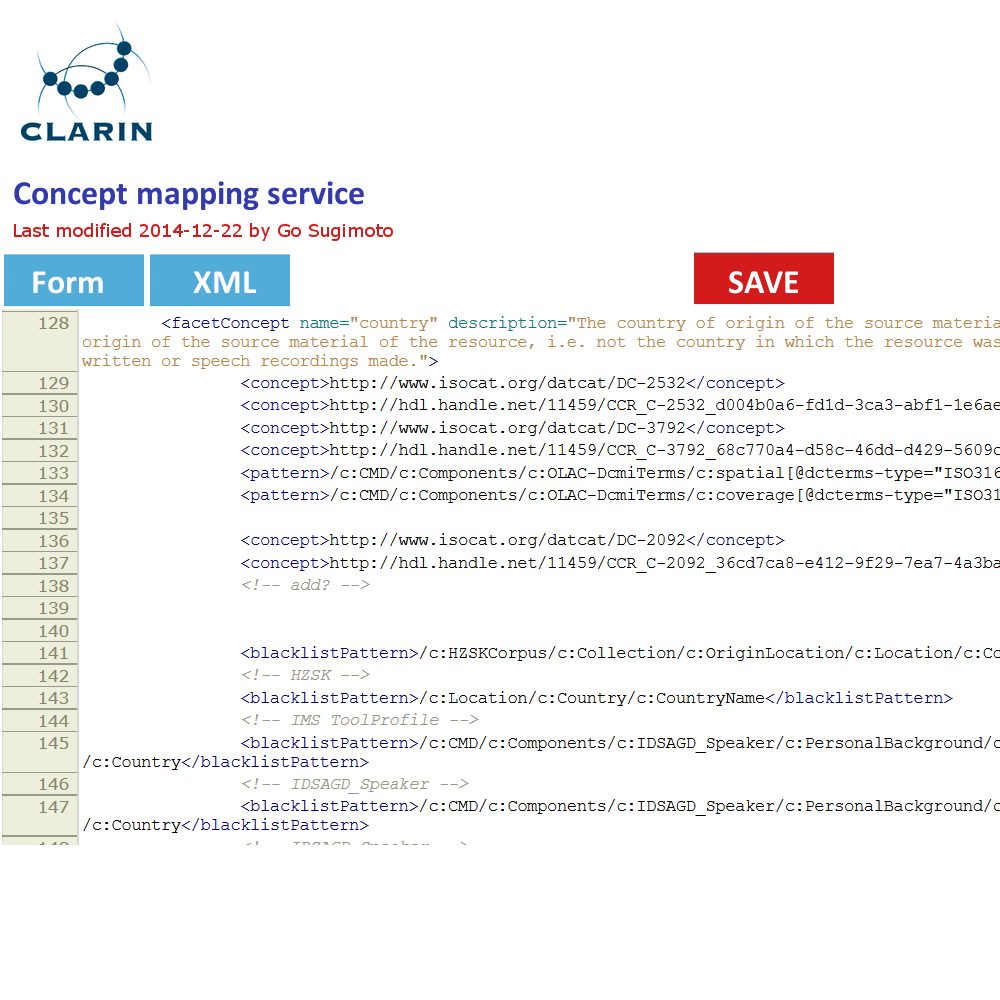
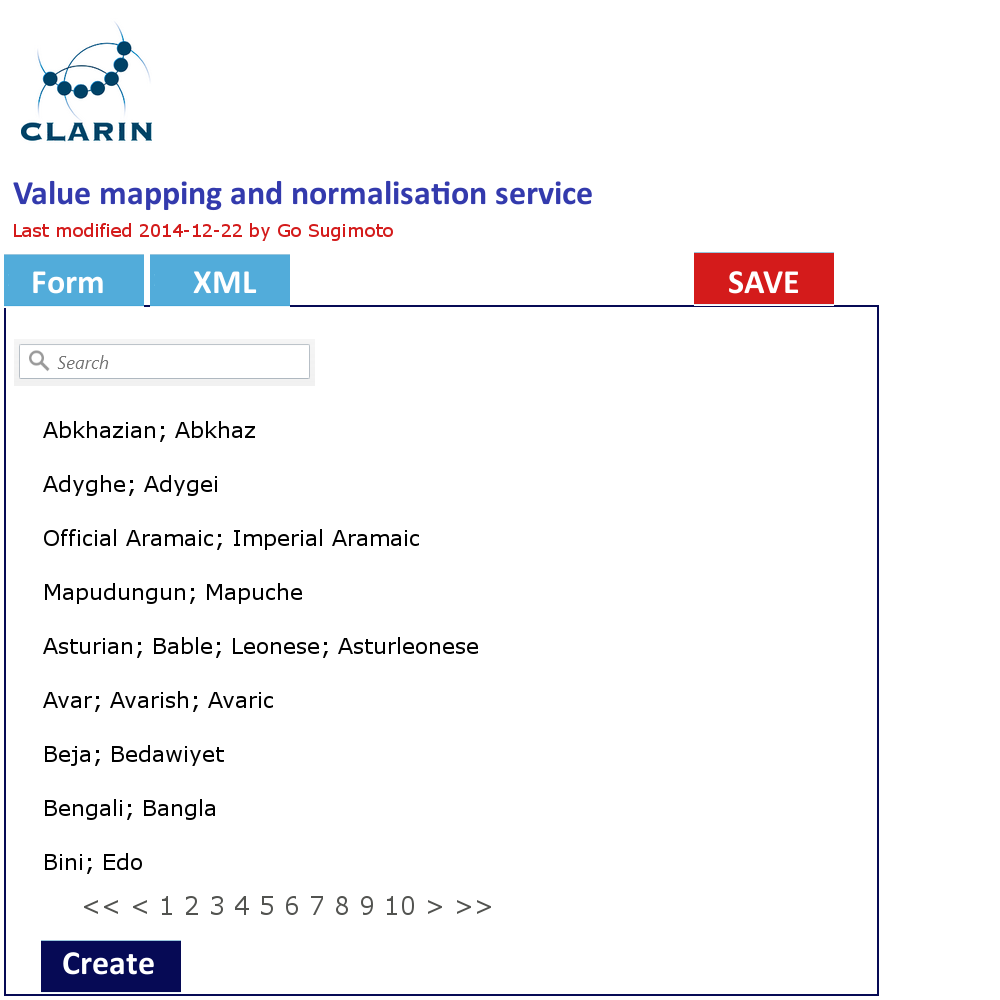
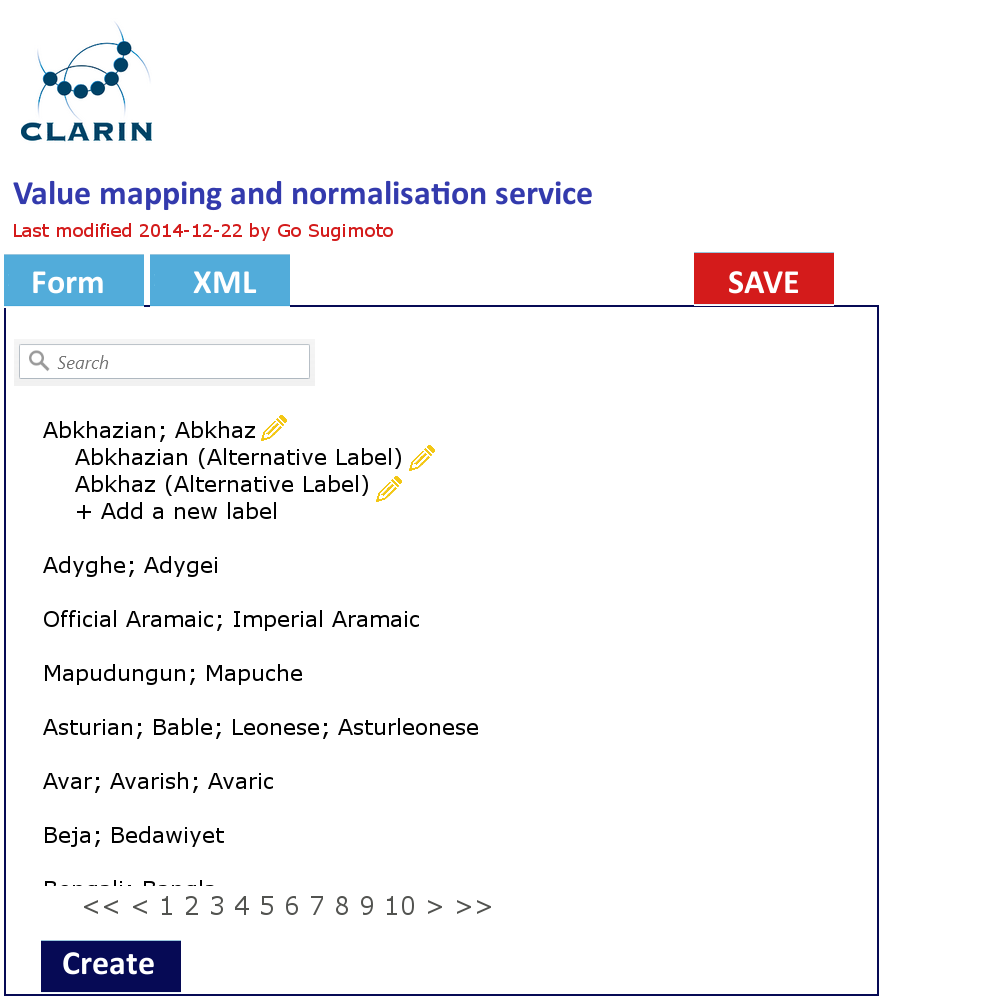
In addition to the data management view of the Dashboard, it can offer a very simple GUI tool (eg a web form interface) to create and edit the concept mapping and the value mapping and normalisation (See figures below). It should translate the data filled into XSLT files (or equivalent) with which the data transformation/mapping will be carried out. Direct XML editing is also possible. The tool will reduce the work involving CSV, TXT, XML, XSLT by introducing a simple yet powerful collaborative web service within the Dashboard framework. Desirably, the editing in the form will not just typing a value itself, but provide a modal window to search and select from relevant extra services (CCR, CLAVAS) (note: there is no mock-up below for this function), so that the curator can double-check with and controlled by the mapping and normalisation values via API/auto-complete.
Concept mapping interface in line with the XML code structure Value mapping and normalisation interface in line with the XML code structure
The enhanced MD authoring tool will communicate with the extra CLARIN services including the (Centre Registry), Component Registry, CLAVAS, and CCR. The base of this tool already exists in different CLARIN centres. COMEDI in Norway and DSpace in Czech/Poland? are two of the good examples. The new tool may include the functionalities as follows (but not limited to):
- Import of Component Registry CMDI profiles (especially the recommended profiles which will be defined by the curation team soon) and selection of them to create metadata (MUST)
- Export of a new CMDI profile defined by a data provider to the Component Registry, and save it in there (MUST)
- Use of controlled CMDI components/elements (mandatory fields and occurrence etc), when defining/editing a profile (MUST)
- Browsing CCR concepts and create a link, when defining/editing a profile (MUST)
- Simulation of VLO display based on the defined profile (MUST)
- Import and export of the XML Schema of a CMDI profile (SHOULD)
- Use of controlled vocabularies (CLAVAS) when filling the metadata records (MUST)
- Browse the data quality report based on the metadata created. If the data is not compliant, it will include warnings to explain the consequences. (SHOULD)
- The MD authoring tool (including the enhanced functionalities above) will be modualised to be split from the local application, so that it can be re-used in other CLARIN data providers and centres, as well as the future possibility to be included in the CLARIN central environment (see Phase III). (COULD)
- Link checker which lists broken links (COULD)
[Mockup will be inserted here]
Those developments are aligned with the CLARIN Plus tasks. In particular, it concerns about T 2.2 Metadata quality improvement which consists of T 2.2.1 Metadata benchmarking and curation, T 2.2.2 Improved harvesting workflow, and T 2.2.3 Reinforced concept registry.
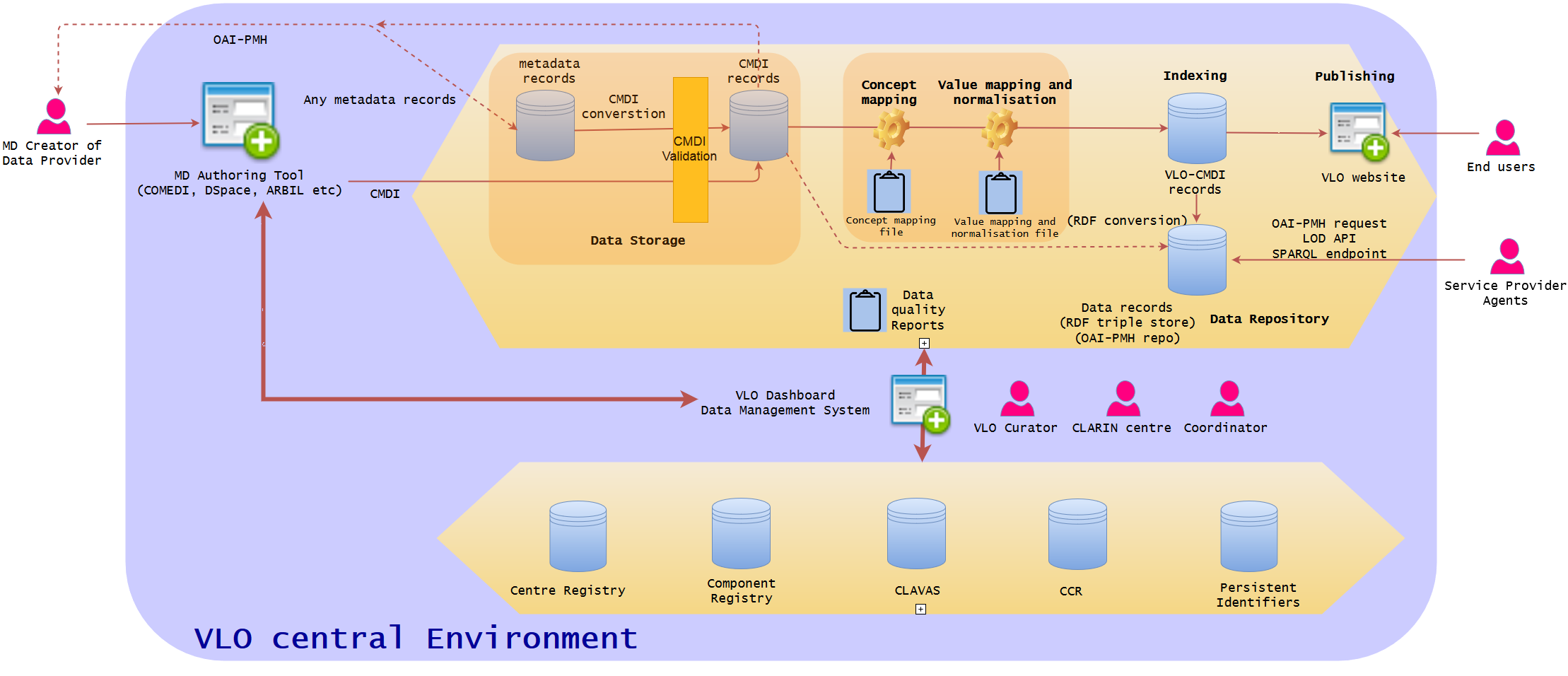
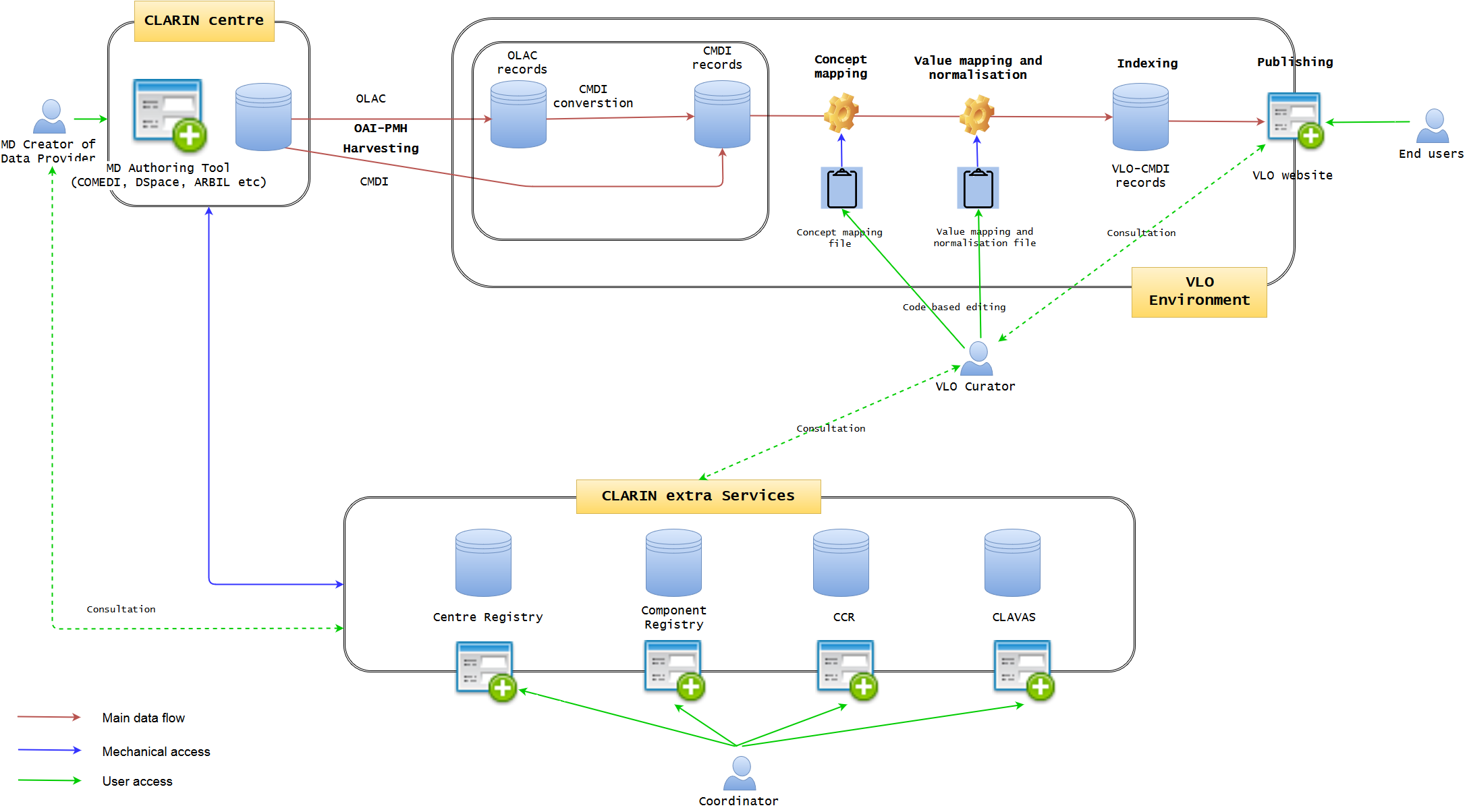
Phase II - Extended Dissemination Information Package (DIP)
OAI-PMH repository / RDF triple store /LOD API

After establishing a best practice ingestion data workflow, this phase is rather simple. It can be skipped, if it is not needed or to be incorporated in another phase. In essence, it will add more sophisticated Dissemination Information Package (DIP) module where data records will be stored in more advanced format(s) and could be accessible via different methods.
A data repository will be added for data dissemination. It could be just a OAI-PMH repository where third party service providers could harvest CMDI-VLO data from CLARIN. When the mapping of CMDI-VLO schema to RDF is defined, it could be RDF triple store where the data is stored in this format, or DB2RDF would be another solution. It could be accessed as LOD via API as well as a data dump and a new SPARQL endpoint. It is not still known if the data should come from CMDI or VLO-formatted CMDI. The associated concepts (CCR) and vocabularies (CLAVAS) are probably not needed to be deposited here, as they are available and accessible as separate web services (but see Phase III, if they are integrated, it might be another story).
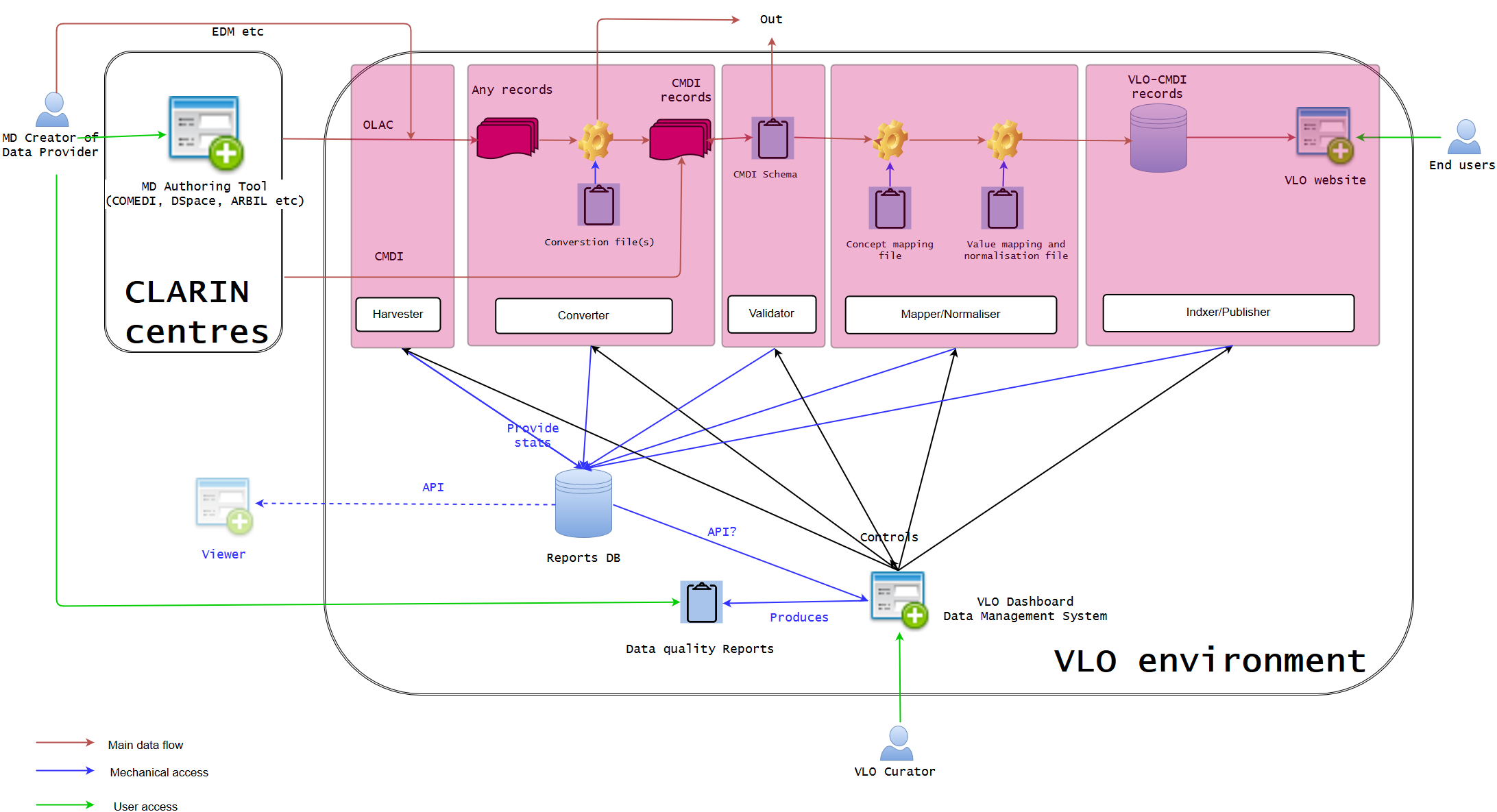
Phase III - VLO central service
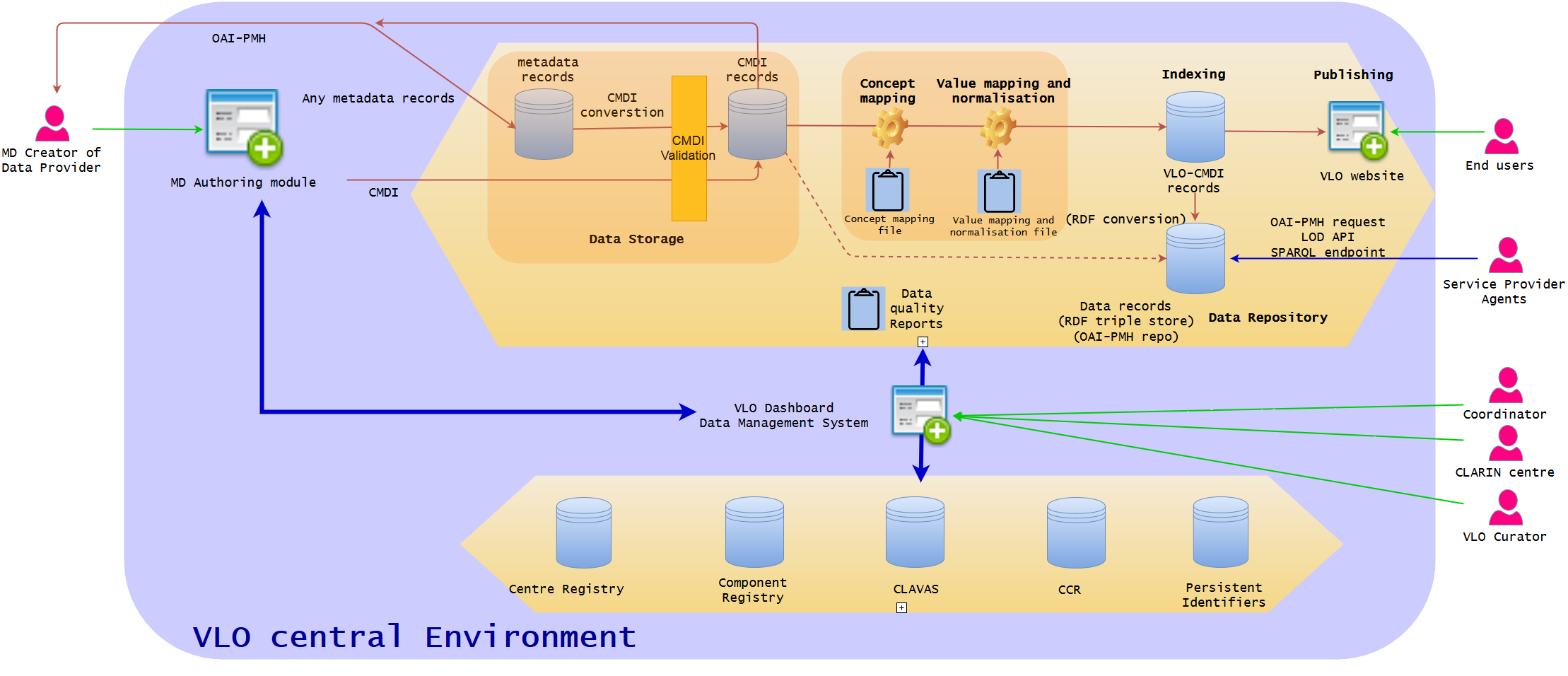
Integration of CLARIN centre services (MD authoring tool) and extra services (Centre Registry, Component Registry, CLAVAS, CCR, and Persistent Identifier) with one Dashboard VLO data management system
This is rather an ambitious plan, and should be regarded as a potential. Although it may be a long way to go, it is also good to aim for a more innovative future and we can look back, from the futuristic viewpoint to adjust a course of long-term development strategies.
The phase III is to eliminate redundant services within the VLO framework, and the possibly best solution is to introduce cloud-like central environment where all services are served centrally, and the CLARIN partners will access via two major entry points to manage data in the whole system.
The first entry point is only for data providers to manage their own data. The MD authoring tool will be separated from the local application and integrated in the central service. This means harvesting is not needed any more. The data will be stored directly on the central storage server and the tool will interact with the VLO dashboard from where necessary information is fetched. A data provider can only manage their metadata (not others) by creating profiles, filling the records, and checking the results visually and statistically. If they already have their metadata sets locally, they will be uploaded to the central environment via OAI-PMH. In terms of digital resources, it should be discussed if they should be deposited in the environment, or in the local storage. Although the latter may be more likely regarded as a hybrid system, in theory, both options will work, as far as the metadata points to the right location of the digital resources (which is already the case). The metadata in the central environment can also be easily exported to the local systems, if required.
The second entry point is for VLO central team to work on the VLO related central services. This catch-all team includes (but not limited to) VLO curators who primarily manages the concept mapping and facet value mapping and normalisation, CLARIN centres which work for Centre Registry, and CCR coordinators who are responsible for maintaining CCR. The organisation of the VLO internal team needs to be re-defined, however, the intention of this entry point to avoid having and maintaining several web services in separate domains which requires the users to visit different websites to log-in multiple times, because the roles of the central team is often hugely overlapping and closely related at least.
It is understandable to argue that the extra services are good to be operated in a distributed manner, but, they also have disadvantages. There is a tendency that the location of the servers/services (i.e. domain) are strongly connected to the political and economical ownership of them. If CLARIN would like to be a real borderless European infrastructure, there are reasons to ask why they are separated. To clarify the responsibility of the services, it seems more natural to think that all core CLARIN services would be better located and managed centrally in the political and financial sense, as well as technical sense, so that the all administrative issues can be handled centrally. Also, in terms of maintenance of the infrastructure, it is much efficient to put all them together. In particular, the administration work of VLO is closely tied with the curation work as well as the maintenance of the extra services. Therefore, the entry points of the central environment would be desirably minimised (probably with the access with federated ID). When the extra CLARIN services will be placed in the central environment as separate components, the synchronisation of all the VLO services and relevant standard services such as persistent identifiers are also much more consistent, cohesive, reliable, and manageable (under the same clarin.eu domain).
The Dashboard will have an interface to maintain the services (add, delete, edit the components, profiles, concepts, and vocabularies), and the relevant services can be called-up and referenced without visiting another website. For example, when somebody works on the concepts in CCR, the reflection will be dynamically visible in the concept mapping. However, it will not intervene the initial purposes of monitoring the data ingestion pipeline. The VLO curators will still work on the overall data management but they could also access to the abovementioned CLARIN services, if they play two roles. In this way, the communication between data providers and VLO curators is much closer and streamlined in the same framework.
As an option, the Phase III could be implemented with Content Management System (CMS). Strictly speaking, it is not a part of normal VLO data workflow, however, it would be an important development plan, as it is certainly related to VLO record issues (eg. commenting, persistent identifiers, etc). The CMS may work especially well as a end-user management system. If VLO will require more user oriented services, the CMS may make the life of developers easier to manage registered users and user generated content such as tagging, commenting, bookmarking, saved search, uploading, forum, and other social network functionalities. It may also help to quickly build a multilingual website. For more details, please look at Implementing CMS for VLO.
Issues to be considered
- Local repository applications (COMEDI, Dspace) needs to be still operational, physically separated from the central environment, unless they want everything to be integrated in CLARIN. Only the MD authoring tool/module needs to be extracted and attached to the central environment where metadata storage also takes place. Maybe the CMDI data would be pushed to the local repository. >> Check how the CLARIN centre repositories work and modify the workflow accordingly.
- There should be different levels of access permission to the VLO Dashboard. Although some members of CLARIN team have multiple roles, it is envisaged that there should be at least three different roles for the Dashboard: data providers/CLARIN centres who work on the data ingestion, VLO curators who work on the overall data ingestion of all the data providers, and the coordinators (Centre Registry, Component Registry, CLAVAS, CCR, Persistent Identifiers) who work on the maintenance of the corresponding services. It is recommended that the last two roles would become one, because their jobs are closely related. On top of the three roles, there should be admin accounts which can do everything with the central management, and are assigned to the lead VLO developer(s). >> Clarify the roles of the three stakeholders.
It is very important all the technical implementation in this document follows the VLO guidelines and recommendations which will indicate what to be done to organise and manage the metadata for the sake of the end-users.
Attachments (19)
- Copy of Current VLO data workflow.png (176.4 KB) - added by 9 years ago.
- Copy of Go - VLO data workflow_longterm.png (177.1 KB) - added by 9 years ago.
- MappingInterfaceForm.png (66.8 KB) - added by 9 years ago.
- ConceptMappingInterfaceForm2.png (89.5 KB) - added by 9 years ago.
- MappingInterfaceXML.png (91.9 KB) - added by 9 years ago.
- ConceptMappingInterfaceXML.png (115.2 KB) - added by 9 years ago.
- ConceptMappingInterfaceXML.2.png (115.2 KB) - added by 9 years ago.
- MappingInterfaceForm.2.png (66.8 KB) - added by 9 years ago.
- MappingInterfaceFormSelected.png (73.3 KB) - added by 9 years ago.
- Go - VLO data workflow(3).png (195.4 KB) - added by 9 years ago.
- Go - VLO data workflow(2).png (204.4 KB) - added by 9 years ago.
- Dashboard_UI_MockUp.png (52.0 KB) - added by 9 years ago.
- VLO data workflow current .png (167.5 KB) - added by 9 years ago.
- VLO data workflow Phase 2 .png (214.2 KB) - added by 9 years ago.
- VLO data workflow Phase 3.png (191.8 KB) - added by 9 years ago.
- VLO data workflow Phase 1.png (193.1 KB) - added by 9 years ago.
- WorkflowNow.png (180.5 KB) - added by 9 years ago.
- Workflow2.png (210.2 KB) - added by 9 years ago.
- Dashboard workflow.png (227.6 KB) - added by 9 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
.png){kind=link}
.png){kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}